Talk:Fast inverse square root/Archive 1
| This page is an archive of past discussions. Do not edit the contents of this page. If you wish to start a new discussion or revive an old one, please do so on the current talk page. |
inverse = reciprocal
sqrt is a function. An inverse function is defined here https://en.wikipedia.org/wiki/Inverse_function. should not inverse sqrt be the function f(x)=x^2 and not f(x)=1/sqrt(x)?
I'd vote for a name change here. Reciprocal sqrt https://en.wikipedia.org/wiki/Reciprocal_%28mathematics%29 — Preceding unsigned comment added by 2001:6B0:8:0:0:0:0:79 (talk) 09:29, 28 August 2013 (UTC)
It is reasonable to assume the "inverse" in "inverse square root" means the multiplicative inverse of the square root. — Preceding unsigned comment added by 99.236.57.17 (talk) 07:06, 5 September 2013 (UTC)
Distance/norm
Euclidean distance is a property of a pair of vectors. For a single vector, what one computes is the Euclidean norm. Fredrik Johansson 07:42, 16 February 2009 (UTC)
Word Phrasing
Currently there is a dispute whether or not a section should say "approximates" or "outputs an approximation of". My position is that "outputs an approximation of" is correct because "approximates" would imply that the code itself is an approximation of the inverse square root. It is not. Rather, the output of the code is the approximation. Yellowweasel (talk) 17:15, 23 February 2009 (UTC)
- Yellowweasel, you make an enormously intelligent point - it is possible to misinterpret that sentence. In fact I think it's possible to misinterpret the vast majority of sentences in the English language. TungstenCarbide (talk) 17:24, 23 February 2009 (UTC)
- That's true, but my point that my phrasing is less ambiguous still stands. Yellowweasel (talk) 18:23, 23 February 2009 (UTC)
- That's a very good point. I think part of it comes from my somewhat limited ability w/ the language. :) Some of it also comes from the fact that both the bit shift and subtraction operation and the code as a whole produce an approximation for the inverse square root. Since this is a real number operated on in floating point notation with finite precision, almost any operation like that will be an approximation. So unfortunately, the code does approximate. I'm ok with keeping it as "outputs an approximation, though. Protonk (talk) 17:48, 23 February 2009 (UTC)
Not minimax, and improving the iteration
Maybe it should be noted that the proposed constant doesn't yield the minimax approximation.
According to my calculations the mantissa which minimizes the maximum error (while using the same exponent) has a nice algebraic form:

Another informative note is that NR iteration can be replaced with a better cubic convergence rate
iteration, for which the root is still an attractive fixed point when using the same guess.
Thus, by using five FP multiplications (instead of four in standard NR implementation) higher precision is achieved.
I didn't check about quartic and higher order rate of convergence iterations, so it might be a good idea to check them too.
79.180.118.49 (talk) 10:43, 29 April 2009 (UTC)
Blinn
On Beyond3d forum it was mentioned that article http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=595279&isnumber=13035 also describe this method and provide the magic number, it was published in 1997. 85.140.16.93 (talk) 21:31, 29 September 2009 (UTC)
64-bits
Is there a similar magic number to use this code in 64-bit integers? Or are FPUs too fast for it to be important any more? —Preceding unsigned comment added by 82.35.47.138 (talk) 07:59, 18 November 2009 (UTC)
- Pages 10 to 12 in Lomont's 2003 paper (linked in the article as "Fast Inverse Square Root") gives the constant r0 that can be applied to 64 and 128 bit representations. -84user (talk) 13:21, 18 November 2009 (UTC)
0x5fe6eb50c7b537a9 is the optimal magic number in 64 bit. See "Exact Solution" — Preceding unsigned comment added by 207.179.179.226 (talk) 12:23, 31 May 2012 (UTC)
Tried to clarify some terminology
I tried to clarify some aspects of terminology. In particular, two's complements integers do not have true sign bits (sign bits apply only to signed magnitude). Since we are only dealing with positive numbers here, I tried to use that to simplify the explanation. I removed the equation "I=Si*2^{31}+E*2^{23}+M" as I believe it is incorrect because the target type is a signed int. I used the term aliasing (with a link) rather than converting, as converting is less well-defined. Superm401 - Talk 08:11, 18 November 2009 (UTC)
Wierd casting in example
In the example listed under "Overview of the code", it has two casts, first to an integer and then back to a floating point value:
int i = *(int*)&x;
x = *(float*)&i;
What is the reason for all the de-references? Unless there is some magic going on that I'm unaware of, this is absurdly over-complex (and more expensive) version of:
int i = (int)x;
x = (float)i;
118.209.49.91 (talk) 10:23, 24 November 2009 (UTC)
- It's not a conversion to int, but a conversion to pointer to int. Annotated:
int i = *(int*)&x; // Initialize i with the value pointed to by [the address of x, converted to type "pointer to int"]
- It should be noted that this pointer conversion yields an unspecified pointer value, and the result of dereferencing such a pointer value is undefined. On many implementations, what happens is that the actual bits that make up the x object is interpreted as if the object was of type int (otherwise the algorithm wouldn't work). Depending on many things, this could be more or less expensive than (int)x, and is very unlikely to yield the same result. decltype (talk) 10:50, 24 November 2009 (UTC)
I believe that the issue here is that the original explanation was confusing because it claimed that the value was "converted" from float to int, which a) is not the case (the longword is treated as an int, but during that operation is the same bit pattern as when the longword was treated as a float), and b) obscures the cleverness of the <strikeout>hack</strikeout> algorithm. I've updated the description to clarify this, and also to note that this will clearly work only with floats represented internally in IEEE 754 format. Cjs (talk) 15:33, 13 February 2011 (UTC)
- Just to make as clear as possible: the code is not converting from a float to an int. It's a trick that grants access to the float so that you can manipulate it's bits directly. — Preceding unsigned comment added by 852derek852 (talk • contribs) 06:08, 14 April 2011 (UTC)
Carmack's pic
Not a big deal, but I think it should remain because while Carmack didn't originate the code, it is often associated with him personally and his coding mystique generally. Also, it helps to have a topical free image on the subject (cause we probably can't use the Q3 box or a ss). Protonk (talk) 01:46, 4 December 2009 (UTC)
- I don't think it's all that important either, but Carmack admits to not writing the code and this article cites a few sources lending credence to this. Pictures aren't for mere decoration and including Carmack's seems misleading. Now if we had pix of the suggested progenitors of the algorithm, Cleve Moler & Greg Walsh... --Cybercobra (talk) 02:08, 4 December 2009 (UTC)
- Fair enough. I've adjusted the caption. Thoughts? Protonk (talk) 06:24, 6 December 2009 (UTC)
- Tweaked slightly further; the recaptioning sufficiently addresses my objection. --Cybercobra (talk) 06:36, 6 December 2009 (UTC)
- Fair enough. I've adjusted the caption. Thoughts? Protonk (talk) 06:24, 6 December 2009 (UTC)
This is stupid. Why don't we just reference Carmack for any piece of code, regardless of whether he had anything to do with it? Rhetorical question - we shouldn't. Retarded fanboys keep reverting the removal edit...204.77.163.4 (talk) 17:14, 14 January 2013 (UTC)
- Hey, I specified the reason in edit summary, have you read it? Carmack has nothing to do with code itself, but surely has something to do with (and maybe I should say, also plays an important role in) the culture and investigation behind Fast InvSqrt, I think that's the point. - Dr. Cravix ♪Eternal Reminiscence 01:01, 15 January 2013 (UTC)
Pun Intended?
Nice one: shortly after the discussion on ray tracing: "shed some light on possible methods." —Preceding unsigned comment added by 75.49.221.60 (talk) 04:17, 24 January 2010 (UTC)
1.5f
Does 1.5f (seen several times in the code snippets) mean a single-precision constant, or what? It ought to be explained. —Tamfang (talk) 20:49, 22 February 2010 (UTC)
Cite for code
You can pick and choose a cite. The beyond3d one works nicely. I don't know how to physically cite it without making the page look ugly. Protonk (talk) 19:52, 31 October 2010 (UTC)
Copied from my talk page
Hi! Today I edited the 'Fast inverse square root' article, and noticed that you changed it back. The code as is presented now is a normal first order approximation that completely ignores the (zeroth order) approximation where this article is all about (and uses a very silly zeroth order approximation instead). The code I inserted was the original code as present in the sourcecode of Quake 3. Can we change it back?
Geert — Preceding unsigned comment added by 85.149.168.68 (talk • contribs)
/*
** float q_rsqrt( float number )
*/
float Q_rsqrt( float number )
{
long i;
float x2, y;
const float threehalfs = 1.5F;
x2 = number * 0.5F;
y = number;
i = * ( long * ) &y; // evil floating point bit level hacking
i = 0x5f3759df - ( i >> 1 ); // what the fuck?
y = * ( float * ) &i;
y = y * ( threehalfs - ( x2 * y * y ) ); // 1st iteration
// y = y * ( threehalfs - ( x2 * y * y ) ); // 2nd iteration, this can be removed
LHS and Type Punning
I didn't see where this was addressed in the article, but I'm pretty sure this method is no longer optimal because it invokes two Load-Hit-Stores. There's a float-to-int conversion then an int-to-float conversion. The FPU gets beaned on the head to pun the type and the FP register stacks have to go all the way out to main memory, and all the way back to ALU registers.
Here's a better article from Some Assembly Required that discusses this.
Obviously this is a major piece of game-development history and should be recorded, but it should be noted as sub-optimal to modern hardware. —Preceding unsigned comment added by GameMogul (talk • contribs) 03:18, 22 November 2010 (UTC)
- You are mistaken. The whole point of the trick is that because of the way floats are represented, you can get a really good ballpark estimate just by twiddling some of the bits.
If you wanted a ballpark estimate of the square root of (0.45636*10^6), you would just divide the exponent and the number by two, to get about 0.23*10^3 - that's what they're doing here, but it just so happens that it works a lot better in base 2. What you (and I suspect a lot of other people) think is a float to int conversion is really just a language construct that allows you to manipulate the bits of the float directly. — Preceding unsigned comment added by 852derek852 (talk • contribs) 05:57, 14 April 2011 (UTC)
McEniry dead link
Looks like the McEniry paper and website vanished from the face of the earth (and wasn't archived by the wayback machine?). I have a copy of the paper and will provide it on request, but I obviously can't upload it anywhere without permission from the original author. FUTON or not, McEniry's explanation is still the most technically complete of the three major technical explanations and I think the cite should remain in the article. Protonk (talk) 21:49, 11 January 2011 (UTC)
Take out the F-bomb comment
I recommend the "what the f...?" comment should be removed from the sample source code.
Yes, I know this is in the cited source, but it is not relevant to the subject at hand (except to show that someone who worked with the Quake code didn't understand the algorithm). It isn't appropriate to the discussion of a mathematical algorithm and isn't necessary in order to highlight or clarify the algorithm's use of the "magic number" (which is adequately discussed elsewhere in the article). And as long as it remains, it's going to attract attention from well-meaning vandalism fighters and waste lots of people's time to no good end. If this were an article on the subject of vulgar language, a biography of someone known for his/her colourful speech, etc., then using this sort of language in an exact quote might be justified per WP:CENSOR — but this isn't that kind of article at all.
The idea that the expletive needs to be retained for the sake of the integrity of the cited source isn't (IMO) a good enough argument; some material (C preprocessor stuff) has already been edited out for clarity, so there is a precedent for removing other extraneous portions of the quoted code. And secondary sources (which it would generally be better for us to use anyway per WP:PSTS) appear to exist online which discuss this algorithm without using the word in question.
In an effort to get a wider consensus (in whiever direction) on this question, I'm going to post a pointer to this discussion on the talk pages of the video games and computer science wikiprojects. Richwales (talk · contribs) 05:17, 18 January 2011 (UTC)
- Comment: How would removing this from the code help if people know about and would just add it back in?陣内Jinnai 05:27, 18 January 2011 (UTC)
- Either we're quoting the original code or we're not. If we're quoting the original code, it needs to stay in. If we're not, we should write our own pseudocode rather than leaving a bowdlerized version in place and trying to pass it off as a direct quote, or even worse presenting a partial copy as our own without attribution. —David Eppstein (talk) 05:36, 18 January 2011 (UTC)
- It doesn't seem necessary, but I don't see how it could be removed without completely throwing off the composition. If you can think of a way to axe it while keeping the structure intact, I'd vote to delete it. JimmyBlackwing (talk) 05:46, 18 January 2011 (UTC)
- I oppose this, for reasons mentioned on my talk page. Protonk (talk) 05:50, 18 January 2011 (UTC)
- It's not clear to me how removing the comment would be "completely throwing off the composition". Can you clarify? As for "either we're quoting the original code or we're not", do you feel the same way about the five lines of C preprocessor material that have already been taken away from the original source (and if not, why not)? Alternatively, since WP:PSTS advises using secondary sources wherever possible, maybe we should replace this primary source quote with a secondary source illustrating the algorithm (but with the word in question censored) — possibly this. That would also address the concern about people who "know about and would just add it back in" — if the unexpurgated comment isn't in the quoted secondary source, there's no justification in our adding it in unless there is a pressing need to discuss the specific issue of why the comment was originally there. Richwales (talk · contribs) 05:59, 18 January 2011 (UTC)
- Stackoverflow is not a reliable source. —David Eppstein (talk) 06:02, 18 January 2011 (UTC)
- I think this is a lot of fuss over the word "fuck"--especially not used as a verb. I'll reiterate (for the benefit of everyone else, rich has seen it), CENSORED is not there because we are purists it is there because censoring stuff is a pain in the ass even if we make an effort to be as true as possible to the original source material. Do we put asterisks in? Is that too provokative? Do we remove the line entirely? Just the word? There are a hundred permutations of possible censored versions (to say nothing of the effort involved in finding a secondary source which might quote the code but omit the comment) and only one original version. It is just simpler to say "this is how the source was in quake three, this is how we are presenting it". Also, I'm not sure what the importance of the C preprocessor stuff you keep mentioning is. We also didn't quote the rest of q_math.c or the entire rest of the trunk. That isn't a reason for or against quoting an expletive in a comment. Protonk (talk) 06:30, 18 January 2011 (UTC)
- The 2003 Lomont paper ("Fast Inverse Square Root"), already cited as a source in the article, covers the algorithm at considerable length and includes snippets of code which (I think) would adequately illustrate the algorithm. Further, as a secondary source, this would seem (per WP:PSTS) to be preferable — or at least entitled to a presumption of being preferable — to a verbatim quote from the Quake III Arena source code. Remember that the article is about the algorithm — not necessarily specifically about the Quake III Arena implementation of the algorithm — so quoting code from the Lomont paper should be fine even if it isn't precisely the same as the Quake version. If sample code from the Lomont paper were used instead of the excerpt from the Quake code, the article can still say that the algorithm was used there, and the Quake code can be cited as a source, but without having to include the actual Quake code in the article. An additional source I found that might be worth using is this article from the University of Waterloo Electrical and Computer Engineering Department — again, something that avoids dropping the F-bomb. If the subject matter can be more than adequately illustrated (and done so without undue pain, no less) with a good source that avoids the contentious word, then I really see no reason not to go that way. I'll freely admit that I'm a prude, but I honestly think this is a worthwhile point even without trying to invoke prudishness. Richwales (talk · contribs) 07:28, 18 January 2011 (UTC)
- Recommend using article found by Richwales above. It's a secondary source and further explains the theory, which are both preferred. Although WP is not censored, there's no need to stir the pot if we don't have to. --Teancum (talk) 14:44, 18 January 2011 (UTC)
- I take issue with the claim that the article is about the algorithm and not its incidence in the Q3 source code. The whole reason why the code generated as much interest as it did is because it came from id. The bit shift integer constant thing actually predates Q3 even in published literature (see Jim Blinn's floating point tricks), but the opacity of the code and the mystique of the venue brought attention to the code itself. Part of the article is indeed about explaining why a bit shift could stand in for FP division in some cases but that is both because the reliable sources on the subject focused on explaining the how/why of it and because informing the reader required a bit of exposition. Protonk (talk) 17:02, 18 January 2011 (UTC)
- The 2003 Lomont paper ("Fast Inverse Square Root"), already cited as a source in the article, covers the algorithm at considerable length and includes snippets of code which (I think) would adequately illustrate the algorithm. Further, as a secondary source, this would seem (per WP:PSTS) to be preferable — or at least entitled to a presumption of being preferable — to a verbatim quote from the Quake III Arena source code. Remember that the article is about the algorithm — not necessarily specifically about the Quake III Arena implementation of the algorithm — so quoting code from the Lomont paper should be fine even if it isn't precisely the same as the Quake version. If sample code from the Lomont paper were used instead of the excerpt from the Quake code, the article can still say that the algorithm was used there, and the Quake code can be cited as a source, but without having to include the actual Quake code in the article. An additional source I found that might be worth using is this article from the University of Waterloo Electrical and Computer Engineering Department — again, something that avoids dropping the F-bomb. If the subject matter can be more than adequately illustrated (and done so without undue pain, no less) with a good source that avoids the contentious word, then I really see no reason not to go that way. I'll freely admit that I'm a prude, but I honestly think this is a worthwhile point even without trying to invoke prudishness. Richwales (talk · contribs) 07:28, 18 January 2011 (UTC)
- We should quote code verbatim from a reliable source. Doesn't have to be Quake, but it is preferable for the quote to be a self-contained C function. Pseudocode could possibly work, but due to the low-level nature of the code, I personally wouldn't advise it. As to the main issue: WP:NOTCENSORED; hwoever, since the comment is only tangentially relevant and there are apparently other sources we could quote, swapping out the code wouldn't be unreasonable. --Cybercobra (talk) 08:41, 18 January 2011 (UTC)
- Personally, I fail to see this as a WP:CENS issue. If we quote a source, but change something, we are no longer quoting – we are deriving new work. If we are going to remove the line, then we should also specify a footnote explaining what we removed (
"// what the fuck?") and why we have removed (profanity unnecessary for context) it. And even then I would argue that this is not contextually insignificant. — HELLKNOWZ ▎TALK 09:14, 18 January 2011 (UTC) - I would remove the whole code sample from the article. Code samples in general do very little to further understanding of the subject, beyond copy-pasting to produce working code. This code sample in particular has poor, non-descriptive comments (regardless of expletive) as well as abusing C syntax to make it fairly unreadable. The quoted code is therefore of limited usefulness to someone wanting to understand the subject or, specifically, its C implementation. It seems like the main reason this code is even here is because it was written by a "celebrity" programmer and that seems like poor justification for inclusion. Get rid of it and/or replace it with something that does the job better. Ham Pastrami (talk) 05:06, 19 January 2011 (UTC)
- I agree with Ham on this. While I regularly revert editors who try and censor profanities from quotes, A) the profanity is not necessary for the subject at hand, and B) the code sample isn't that great anyhow. We regularly modify quotes in general, unless we were changing the meaning it doesn't really matter. Der Wohltemperierte Fuchs(talk) 14:37, 20 January 2011 (UTC)
- While I don't care much one way or the other about the "f-bomb" in the comment, I strongly disagree with removing the code. The code expresses more precisely how the algorithm works than the English description. In particular, the previous English description (before my update a few minutes ago) was downright misleading, and I didn't realize that there is actually no conversion of floating point to integer until I read the code. Cjs (talk) 15:41, 13 February 2011 (UTC)
- I strongly disagree with Ham regarding code samples. Topics that have to do with computer code are almost always (and this case is no exception) clearer with a code sample, to the point where the code sample usually renders the description of what the code actually does redundant (although that doesn't really apply here).
I think the comment shouldn't be removed, because that comment illustrates what the programmers thought of the code when they encountered it. As such it's completely different from removed preprocessor stuff, which didn't hold any meaning that is relevant to the story. But the comment is relevant and I don't think we should remove it just because it might offend someone somewhere. I personally almost never cuss but in this case I don't think it's worth cutting a piece of the story away just to placate a tiny percentage of readers who care more for superficialities than for the story this article is trying to tell. — Preceding unsigned comment added by 82.139.81.0 (talk) 17:49, 17 July 2013 (UTC)
The Input Is Not "Unsigned"
The article claims that, "The algorithm accepts a 32-bit unsigned floating point number." This clearly isn't the case, since the code is using a signed floating point format. Does it perhaps mean to say that the algorithm only works for either non-negative or positive numbers? Cjs (talk) 15:39, 13 February 2011 (UTC)
- You're correct, the algorithm doesn't work for negative numbers. But this is the case with most approximating algorithms, they usually don't account for "bad" input. Max (talk) 19:41, 2 March 2011 (UTC)
- Actually, unless you're willing to mess around with complex numbers, taking the (inverse or "vanilla") square root of a number is pretty meaningless whether its an approximation or otherwise. The particular algorithm doesn't matter - if you're returning an ordinary float, then no algorithm is going to handle negative input. 140.79.21.6 (talk) 22:14, 22 December 2011 (UTC)
- A positive floating point number is not the same as an "unsigned floating point number".Eregli bob (talk) 04:34, 7 October 2012 (UTC)
"Hack"
This edit changed the wikilink from Hacker (term) (originally Hack (technology) to Life hack, which I feel is inappropriate. My complaints about "life hack" as a term aside, what is going on here is absolutely not a life hack. The function is a "hack" insofar as it is an architecture specific solution to a narrow problem in a clever manner. I won't revert it because wikipedia apparently doesn't have an article for "hacks" apart from "hackers", which is bizarre. Does anyone have a better link? Protonk (talk) 18:09, 31 March 2011 (UTC)
- Well now we need to get to my complaint about the term life hack. "hack" modifies life, not the other way around. More to the point, "life hack" is a neologism derived from the word hack as it is meant to be used in this article. Also, there seems to be some confusion (in part perpetuated by the various "hack" articles) that hacks need to be associated with "hackers". That is not the case. I hope you aren't performing similar redirects on the basis of this misapprehension. Protonk (talk) 20:42, 31 March 2011 (UTC)
- I'm finding it difficult to understand your objection, partly because I'm not sure how you are defining the term "hacker". There are several different definitions: Hacker (computer security), Hacker (programmer subculture), Hacker (hobbyist), etc. It would be very helpful to this discussion if you would identify the definition(s) of "hacker" you are attempting to avoid; it would also be great if you could point to a definition of "hack" in an online dictionary that expresses what you believe the term should indicate in this artice. Neelix (talk) 13:51, 2 April 2011 (UTC)
- Quickly finding the inverse square root of a number is not an "everyday" problem. The trick in question is a hack or a kludge, but certainly not a life hack. --Cybercobra (talk) 06:43, 3 April 2011 (UTC)
- I agree with Protonk and Cybercobra. I never heard the term "life hack" before, but from my reading of the Wikipedia article, a life hack seems to be more of a general method or process for simplifying ones life whereas a hack or kludge is a solution to a specific problem. Hence I think "hack" or "kludge" (see Kludge#In_computer_science) is a much better description of the fast inverse square root than a "life hack". Boghog (talk) 06:55, 3 April 2011 (UTC)
- I think the difficulty stems from some confusion about the term "hack" as distinct from "hacker". I'm not even attempting to invoke the term "hacker", nor are many of the articles which point to "hack", so assuming that a nour which describes a process must be categorized by a noun which describes a group of people will cloud the issue. Protonk (talk) 21:20, 4 April 2011 (UTC)
- Hackers (noun) hack (verb) to create hacks (noun). With respect to the fast inverse square root, the last meaning is relevant. However I do not mean to imply that hackers are hacks! ;-) Boghog (talk) 04:12, 6 April 2011 (UTC)
- Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo, IMO. ;) But I was replying to neelix. i think you and i are on the same page. Protonk (talk) 16:19, 6 April 2011 (UTC)
- Hackers (noun) hack (verb) to create hacks (noun). With respect to the fast inverse square root, the last meaning is relevant. However I do not mean to imply that hackers are hacks! ;-) Boghog (talk) 04:12, 6 April 2011 (UTC)
- Quickly finding the inverse square root of a number is not an "everyday" problem. The trick in question is a hack or a kludge, but certainly not a life hack. --Cybercobra (talk) 06:43, 3 April 2011 (UTC)
- I'm finding it difficult to understand your objection, partly because I'm not sure how you are defining the term "hacker". There are several different definitions: Hacker (computer security), Hacker (programmer subculture), Hacker (hobbyist), etc. It would be very helpful to this discussion if you would identify the definition(s) of "hacker" you are attempting to avoid; it would also be great if you could point to a definition of "hack" in an online dictionary that expresses what you believe the term should indicate in this artice. Neelix (talk) 13:51, 2 April 2011 (UTC)
[Sic]
Prompted by the discussion above, I inserted Sic in square brackets after the colorful comments in the source code to indicate that the comments were in the original text and are not a result of vandalism. My additions were reverted by two editors here and here with the explanation that the use of [sic] in this context was either improper or superflous. I believe that the use of [sic] in this context is justified for the following reasons:
The intention of my edit was certainly not as a form of ridicule, but rather to indicate that the passage appears exactly as in the original source (see the lead to the Sic Wikipedia article). Furthermore according the source cited at Sic#Conventional_usage: Several usage guides recommend that a bracketed sic be used primarily as an aid to the reader, and not as an indicator of disagreement with the source.
The usage of [sic] after the source code comments in this article is consistent with the broader definitions of sic as found in the following dictionaries:
- according to the Merriam-Webster dictionary:
sic ... (ca 1859): intentionally so written -- used after a printed word or passage to indicate that it is intended exactly as printed or to indicate that it exactly reproduces an original
Webster's 9th New Collegiate Dictionary (1991)
- according to TheFreeDictionary.com:
sic ... sic1 adv (Communication Arts / Printing, Lithography & Bookbinding) so or thus: inserted in brackets in a written or printed text to indicate that an odd or questionable reading is what was actually written or printed
American Heritage Dictionary of the English Language, Fourth Edition (2000)
Other Applications
Another application might be in fast computation of sines and cosines of angles in a triangle when given the length of the sides x & y. sin(theta) = y/hypothenuse and cos(theta) = x/hypothenuse. The hypothenuse is, of course, sqrt(x^2+y^2). Powerslide (talk) —Preceding undated comment added 19:48, 20 January 2012 (UTC).
Likewise, when cos(theta) or sin(theta) is already given, then tan(theta) can be quickly calculated by using the fast inv. square root; i.e. tan(theta) = cos(theta) * 1/sqrt(1-cos(theta)^2; and tan(theta) = sin(theta) * 1/sqrt(1-sin(theta)^2). I don't see these applications are covered in the wikipedia article Powerslide (talk)
Faster than fast transform
Is this new development already covered at Wikipedia? [1] Diego (talk) 20:14, 20 January 2012 (UTC)
Sources (tab dump)
http://www.beyond3d.com/content/articles/8/
http://betterexplained.com/articles/understanding-quakes-fast-inverse-square-root/
http://ncannasse.fr/blog/fast_inverse_square_root
http://www.jakevoytko.com/blog/2008/01/28/quake-3s-fast-square-root-function/
http://www.spectrum.ieee.org/print/1643
www.geometrictools.com/Documentation/FastInverseSqrt.pdf
http://www.springerlink.com/content/p31t837025867465/
http://shelfflag.com/rsqrt.pdf — Preceding unsigned comment added by 99.252.117.60 (talk) 14:32, 29 April 2012 (UTC)
Exact Solution
There is an exact solution to the optimal magic constant after one (or possibly more) iterations of Newtons method. See http://eggroll.unbsj.ca/rsqrt/rsqrt.pdf
The optimal magic constant is given by:

where is the solution to


where , is the bias and is the size of the mantissa field of the floating point representation.



This gives optimal magic constants of:
float: "0x5f375a86"
double: "0x5fe6eb50c7b537a9"
quad: "0x5ffe6eb50c7b537a9cd9f02e504fcfbf"
These are mathematically derived and can be confirmed to be the optimal.
The max rel error does not depend on the precession of the floating point representation. The more precise the representation, the closer the error will get to 0.0017511836712202133521251742467001545368 — Preceding unsigned comment added by 99.252.117.60 (talk) 14:45, 29 April 2012 (UTC)
Can somebody add this to the main article? — Preceding unsigned comment added by 99.252.117.60 (talk) 23:18, 17 May 2012 (UTC)
who know where 0x5fe6eb50c7aa19f9 comes from?
I've checked McEniry's paper, his result is 0x5FE6EB50C7B537AA as follows, whose precision is between 0x5fe6eb50c7aa19f9 and 0x5fe6ec85e7de30da(Lomont's):
| “ | Calculating for the double-precision floating-point number, where n = 64 and b = 11 , gives R = 0x5FE6EB50C7B537AA . | ” |
| — McEniry 2007 | ||
I've STFG but cannot find any ref about the origin of 0x5fe6eb50c7aa19f9. could anyone find and add some refs for that? Thanks in advance!![]() - Dr. Cravix ♪Eternal Reminiscence 03:07, 16 May 2012 (UTC)
- Dr. Cravix ♪Eternal Reminiscence 03:07, 16 May 2012 (UTC)
About The "magic number"
I feel that the section "The 'magic number'" has almost nothing to do about why the magic is the 0x5f3759df. It just tried to imply that 0x5F is and 0x3759df is . In another word, it is all about why the line i = 0x5f3759df - (i>>1); would work with a given number R. And it did not mention (at least not write clearly) that the highest bits of the magic number has to be 0x5f(or 0x60 which would also works in some cases). It would be much better to explain that, " With given b=7, . And right shifting one bit of 190(0xbe) just equals 95(0x5f), which is the highest byte of the designated 'magic number' 0x5f3759df.



Would it be better if the article is organized in such sequence:
- Motivation
- Overview of the code
- Aliasing from floating point to integer
- Shift and subtract ( contains the most part of the section "The 'magic number'" except the last paragraph. Talks about why the shifting and subtraction would converge to the inverse squre root of x so fast. )
- Newton's method ( which is originally a independent section. In fact, this method is used in the code. So it would be better to talk inside the section "Overview of the code". )
- Accuracy
- The 'magic numbers' ( talks about why the number 0x5f3759df is picked, along with the other numbers, such as the lomont ones and the double ones, etc. )
- The exponent ( talks about cases when the exponent part of the original 32bit float number is even, is odd, according to Lomont's paper. )
- The mantissa ( talks about why the rest of the number would be 0x3759df. Also includes some parts in the section "History and investigation" of the original article. )
- 64 bits magic numbers ( talks about the same method would works under 64 bits float number. )
Inverse square roots are used to compute angles of incidence and reflection ?
This could be clarified - I would have thought Trigonometry. The Inverse square law, on the other hand, is about lighting intensity, not angles.
--195.137.93.171 (talk) 11:11, 7 January 2013 (UTC)
- This has little to do with the Inverse square law. Lighting intensity is generally calculated with Lambertian reflectance which uses the cosine of the angle between the incident light direction and surface normal. This can be calculated using the geometric definition of the dot product, ie. cos(θ)=(N•L)/(|N||L|), which requires the normalization of the light direction and surface normal vectors which can be done with the inverse square root function here. The Inverse square law is not used as often in computer graphics because lights are preferred to have a well-defined and relatively small volume of interaction so rendering engines use attenuation functions with finite domains. Qartar (talk) 18:36, 29 May 2013 (UTC)
It is useful when inverse square laws are involved (as in gravity or electrostatic calculations), or even more generally, when normalising a vector. Suppose you have an arbitrary vector V = (x,y,z) and you want to normalise it so that |V| = 1. This is done by computing V/|V| = V/sqrt(x² + y² + z²), and this is not restricted to three dimensions. In short, 1/sqrt(anything positive) is often useful. NickyMcLean (talk) 20:31, 7 January 2013 (UTC)
Authorship
It looks that there had been further insights about the autorship of the original code. See Greg Walsh in http://www.beyond3d.com/content/articles/15/. I don't want to edit the page because it's an old source and I don't know if there is some newer knowledge bout the issue. — Preceding unsigned comment added by 195.57.29.21 (talk) 12:52, 16 May 2013 (UTC)
Inverse square root of zero
It might be worth noting that this function does not return a NaN for zero, which may be advantageous for normalization of data which may contain zero-vectors. Qartar (talk) 18:16, 29 May 2013 (UTC)
Not doing 2nd iteration is a mistake
Be aware that you should not comment out the last line like:
// y = y * ( threehalfs - ( x2 * y * y ) ); // 2nd iteration, this can be removed
It seems that adding further iteration of this doesn't improve the result much, but adding it once is very important, at least while using 64 bit numbers (double). The following prime number generator won't work as intended if this line is not in the "isqrt" method. Run the following code and comment it out, you will get wrong primes:
compare to: http://primes.utm.edu/lists/small/millions/ — Preceding unsigned comment added by Xeus2001 (talk • contribs) 17:38, 15 February 2014 (UTC)
Higher precision by a minor tweak
As the computed value is always less than or equal to the exact value, a minor tweak can be performed to improve the accuracy by around 1 binary bit.
const float threehalfs = 1.5F;
When the magic number is set to 0x5f375a86 and using one iteration of Newton's method:
-
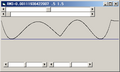 Relative error when threehalfs=1.5.
Relative error when threehalfs=1.5. -
 Relative error when threehalfs changed to 1.500947.
Relative error when threehalfs changed to 1.500947.


Switching the magic number from 0x5f3759df to 0x5f375a86 yields a slight change on the Root-mean-square deviation of relative error from 0.00111871770620 to 0.00111936422007. But by replacing 1.5 with 1.500947, the RMS drops to 0.00057663054694.
If using two iterations, the original algorithm produces RMS=0.00000246611829. Replacing the first 1.5 with 1.50091922283173 and the second 1.5 with 1.50000047683716 yields RMS=0.00000038876154, an improvement of around 3 bits (1×2+1). Also, It's almost reaching full precision of IEEE single FP.
Furthermore, for double and quad FP, another iteration produces (1×2+1)×2+1 bits, and so on. The corresponding "good" threehalf value can be found not that hard (not sure for optimal).
| This page is an archive of past discussions. Do not edit the contents of this page. If you wish to start a new discussion or revive an old one, please do so on the current talk page. |