Welcome to the Wikipedia Mathematics Reference Desk Archives
The page you are currently viewing is an archive page. While you can leave answers for any questions shown below, please ask new questions on one of the current reference desk pages.
I remember an old math teacher taught me a method, given numbers n1, n2, etc. , to determine a function f(x) for which f(1) = n1, f(2) = n2, etc., but I forget how. I recall that it had something to do with subracting the first two terms with each other, then subtracting this difference with the 3 number, and so on until you got 0, but I'm not sure about this. There were also a lot of factorials involved. Does anyone know what I'm talking about? —Preceding unsigned comment added by 74.15.138.134 (talk) 02:30, 16 June 2009 (UTC)[reply]
Note that, trivially, one can always define a function on the natural numbers to have those values (just definite it like that!). However, with the other information you have provided, it appears that you want a polynomial having those values restricted to the natural numbers. Let me give you the intuition behind this:
Suppose the difference between n1 and n2 is the same as the difference between n2 and n3 which is the same as the difference between n3 and n4 etc... Then the desired function is linear; that is, one may define f(x) = n1 + d(x - 1), where d is the constant difference in question (d could be negative or positive). Observe that this function "works."
On the other hand, if the differences are increasing at a constant rate (and are not themselves constant), the desired polynomial will have a term of degree two. For instance, consider the following values of ni:
n1 = 1, n2 = 4, n3 = 9, n4 = 16 etc...
Observe that the differences are: 3, 5, 7 etc... and that the differences are increasing at a rate of 2. Since the differences are not constant, the function cannot be linear. Therefore, it must be a quadratic since the differences are increasing at a constant rate (if this rate were not constant, we might have to jump to cubics, or even quintics). I think that you can see that the desired function is the "square function" - f(x) = x2.
How would we generalize the above method if we did not know the values of the ni but knew particular differences? Well, we use factorials. If the differences are constant, the function must be linear. If the differences are changing at a constant rate (like above), let di be the ith difference, and let (d') be the difference in the differences (i.e the rate of change of the differences). Then the co-efficient of the x2 in the polynomial is given by (d')/2!. Notice that this agrees with the above where (d') = 2, and we found the co-efficient of the x2 to be 1. See if you can compute the co-efficient of the x in the quadratic. In general, assuming you are familiar with differential calculus, one may observe that the co-efficients seem similar to the co-efficients of the taylor series expansion of an analytic function.
It might be interesting to see if you can generalize the above method to arbitrary ni's where the difference of the difference of the.....differences between the ni's is constant. Depending on how many differences it takes to achieve this constant, one may compute the degree of the desired polynomial. Hope this helps. --PST 04:52, 16 June 2009 (UTC)[reply]
Rmk: According to the historian Florian Cajori, the mathematical term coefficient (from a composition of cum+ex+facio) has been introduced by François Viète. I've never seen it written this way above, with a dash... --pma (talk) 14:16, 16 June 2009 (UTC)[reply]
If a dog is tied to the corner of a shed 6m in width and 3m in length by a rope that is 5m, what is the area within the dog's reach?
I know the answer is 62 m squared, but i can find no way to get it. —Preceding unsigned comment added by 174.6.144.211 (talk) 03:03, 16 June 2009 (UTC)[reply]
Seems like the answer should be 19.75π. There are two regions the dog can get to: one is three quarters of a circle with a radius of 5. This is the area the dog can get to with the rope as a straight line, and is 3/4*52*π m2 == 18.75π m2. The other region is one around the corner of the shed, where the dog still has 2 m of rope (having spent 3 m on the shed side) -- this has an area of 1/4*22*π == π m2. —Preceding unsigned comment added by 24.106.180.134 (talk) 04:18, 16 June 2009 (UTC)[reply]
I just realized that 19.75π is about 62.04. So there we go. --24.106.180.134 (talk) 04:21, 16 June 2009 (UTC)[reply]
The answer puzzled me for a moment until I understood that the dog is outside the shed. —Tamfang (talk) 23:55, 19 June 2009 (UTC)[reply]
I'm having an argument with a friend about how many MLB games there are total in one season. The parameters of the argument are that there are 30 teams, which each play 162 games a season. We disregard both post-season games and any single game tie-breakers at the end of the season. I think there are 162*15 = 2430 games total -- there are 15 pairs of teams, and since each team has to play all of its 162 games with another team, we need to count only half of MLB to get the total. My friend argues that I'm double counting games that the 15 teams I choose play against each other, and that this is not necessarily equal to the number of games that the 15 teams I didn't pick play against each other. He thinks that the only way to know would be to count -- i.e. that simply knowing there are 30 teams and 162 games per team doesn't help you know the total unless you know a lot more about the exact distribution of opponents in the games that each team played. (For people who might not follow MLB: over the course of the season, each team will play the other teams in its division very often, the teams not in its division but in its league not as often, and teams in the league rarely if at all. There are two leagues of 3 divisions, which vary in size from 4 teams to 6. It is not the case that each team plays some set number of games per each opponent team, or that each team faces all of the other 29 teams as opponents.)
Are either of us correct? Is there some formula to quickly determine the total games play per season, or does one need to count?
As I see it, say the Yankees and the Red Sox played a game against each other today. Since their combined effort resulted in one game, we could say that each of them played half a game. Each team in that manner plays 162 half-games per season. So in the complete season, there are 162*30=4860 half-games or 2430 games. You don't have to worry about who played who. 208.70.31.186 (talk) 05:53, 16 June 2009 (UTC)[reply]
Yes, 2430 is correct, assuming you are counting scheduled games, there are often a few rainouts that aren't made up if they don't affect the standings. Sometimes all scheduled games are played, sometimes not. (And you disregard the All-Star game, and pre-season games).--SPhilbrickT 12:40, 16 June 2009 (UTC)[reply]
I have set up a voting page for my daughter's middle name (http://adalinewagner.com/nameme.html). If you don't want to look at it, it is a list of names sent to me by email. Each name has a rating from -2 to +2. Users rate each name in the list (or ignore the name and don't rate it at all). I was wondering what the most accurate algorithm for tallying up the votes may be. The catch is that not every person will rate each of the shown names. So, if 100 people vote, there may be a name with 100 ratings - which makes it obvious that you take the average. There may also be a name with only 1 rating. Taking the average will make that 1 vote be the entire vote. If I'm not explaining this well enough, please let me know. -- kainaw™ 13:26, 16 June 2009 (UTC)[reply]
I think it is a better idea to decide on the tallying method before presenting the choices. Once you have the choices it is often possible to present an "almost fair" tallying method that chooses any winner that is not universally hated. Since there are no fair tallying methods, you are forced to choose between almost fair ones. Probably your best bet given your current polling method is to treat this as a "primary"; any name whose sum or average is positive after the polls closed is moved on to the next round where you ask people to rate the names in order of preference. I would suggest using a Borda count for the final tallying, since it should produce a winner that is not despised by anyone and is moderately pleasing to most. JackSchmidt (talk) 14:05, 16 June 2009 (UTC)[reply]
The simplest way to resolve this is of course to treat each missing vote as a vote of 0 with a lower weight. A slight modification is to use the total average, or the user average, instead of 0. I don't think the problem is well-defined enough to speak in terms of "the most accurate algorithm" - for this you will need a model of the reasons people choose not to vote on a name. -- Meni Rosenfeld (talk) 15:06, 16 June 2009 (UTC)[reply]
Thanks. The main reason for not voting on a name is that the name was added after the person voted and the person has not returned to vote again. Previously, I used a zero for all non-votes. Now, after reading this, I am leaning towards multiplying the average of the ratings which exist by the percentage of people who voted, which will push names with very few votes to an average of zero. -- kainaw™ 15:15, 16 June 2009 (UTC)[reply]
Aren't these two methods identical? Anyway, I do recommend using a lower weight for a missing vote than for an actual 0 vote (which is equivalent to multiplying by some function of the percentage). -- Meni Rosenfeld (talk) 18:35, 16 June 2009 (UTC)[reply]
See this, which illustrates the main flaw with your approach. One way to address this flaw is to normalize each person's votes so that the average vote of each person is 0. So, if you look at all the names that a person voted on, and the average is 0.65, then you would subtract 0.65 from each of that person's votes so that their average is now 0. After doing that, proceed as before; the score of a name is the average of the scores that people who voted on it gave it. Eric. 128.12.170.55 (talk) 21:25, 16 June 2009 (UTC)[reply]
Is one number a power of the other? Time efficiencyedit
Is there any method of finding if a is an integer power of b (where a and b are integers) in faster than logarithmic time? Assuming that arithmetic operations are constant time. Angus Lepper(T, C) 14:34, 16 June 2009 (UTC)[reply]
Logarithmic in what? If you start with calculating , you can do this using operations. -- Meni Rosenfeld (talk) 14:53, 16 June 2009 (UTC)[reply]
Logarithmic in a (my a and b were the other way around from yours). e.g. if a isn't divisible by b, return false; if a = b, return true; otherwise, divide a by b and start over. But your suggestion's obviously faster. Thanks. Angus Lepper(T, C) 15:15, 16 June 2009 (UTC)[reply]
Right, I've edited my post to match your notation. -- Meni Rosenfeld (talk) 16:00, 16 June 2009 (UTC)[reply]
(removing my comment on % operation, just now noticing the use of "power" not "multiple") -- kainaw™ 16:01, 16 June 2009 (UTC)[reply]
If a is a power of b, then the bth root of a will be an integer. Taking a root is a O(log n) function in most computer implementations (any that are worth noting). Testing to see if the result is an integer is a O(1) operation. So, it is logarithmic. -- kainaw™ 16:05, 16 June 2009 (UTC)[reply]
I seriously doubt that the OP's assumption that arithmetic operations take constant time is supposed to apply also to powering. Anyway, "a is a power of b" does not mean that the bth root of a is an integer, but that there exists an integer c such that the cth root of a is b. — EmilJ. 16:16, 16 June 2009 (UTC)[reply]
DJB has a few papers on detecting perfect powers, that might or might not be what you want. See [1] and look for the word "powers". 67.122.209.126 (talk) 16:11, 16 June 2009 (UTC)[reply]
Starting with any triangle it's possible to inscribe a circle, form a triangle from the points of contact, inscribe a circle, etc. Successive triangles will be smaller and it's intuitively obvious that they will tend to equilaterality. But can this be done with quadrilaterals? The largest one must be inscribable by a circle, so its opposite sides must sum to the same amount, and all subsequent ones must be both inscribable and circumscribable, i.e. as well as the condition on opposite sides, the opposite angles must sum to 180°. Is it possible to draw an initial non-square quadrilateral (which I suspect on grounds of symmetry would have to be circumscribable, so that the construction could continue outwards as well as inwards) from which an infinite number of nested circles/quadrilaterals can be drawn, with intuitively the latter tending to squareness as they get smaller?→86.148.185.203 (talk) 15:04, 16 June 2009 (UTC)[reply]
Try an isosceles trapezoid with bases 1 and 3 and sides 2. -- Meni Rosenfeld (talk) 15:50, 16 June 2009 (UTC)[reply]
The inscribed circles wouldn't be concentric in that case, would they? I think requiring concentric circes might force the inscribed polygons to be regular. -GTBacchus(talk) 16:54, 16 June 2009 (UTC)[reply]
No, but I think the shape converges to a square anyway. -- Meni Rosenfeld (talk) 18:38, 16 June 2009 (UTC)[reply]
Do you mean that the circles are concentric in the trapezoid case, or just that concentricness doesn't force regularity? -GTBacchus(talk) 23:25, 16 June 2009 (UTC)[reply]
I mean that the circles aren't concentric, and that concentricness isn't required for (edit: convergence to) regularity. -- Meni Rosenfeld (talk) 23:35, 16 June 2009 (UTC)[reply]
Ah, but if you insist that the circles be concentric, then is regularity forced? -GTBacchus(talk) 08:28, 17 June 2009 (UTC)[reply]
Yes, if a polygon has a circumscribed and an inscribed circles which are concentric, then the polygon must be regular by symmetry. -- Meni Rosenfeld (talk) 10:46, 17 June 2009 (UTC)[reply]
Let's start from your construction with triangles, and let's try to explain the intuitively obvious fact you noticed, about the shape of the triangles, when the construction is iterated. It seems to me a nice geometrical example of some facts in finite dimensional spectral theory.
So, the best thing is looking just at the angles (α,β,γ) of the triangle, and look at how they transform in the construction, forgetting about the size, that is not relevant to the shape. There is an even more important reason to consider the angles (and not, e.g. the edges or the cartesian coordinates). The new triangle has angles ( (β+γ)/2 , (α+γ)/2 , (α+β)/2 ): it's a linear transformation. It is represented by a symmetric 3x3 matrix A, with 0 on the diagonal, and all remaining entries 1/2. The eigenvalues of A are 1 (simple) and -1/2 (double). Now, consider the initial triangle, with angles x:=(α,β,γ). Write this 3vector as x = u + v, where u:= (π/3, π/3, π/3) is in the eigenspace of 1, and v is in the eigenspace of -1/2. Then you have for the k-th iterate: Akx= Ak(u + v)=u +(-1/2)kv, that converges exponentially to u, that is, geometrically, the zoomed triangles approach exponentially the equilateral triangle. --pma (talk) 17:41, 16 June 2009 (UTC)[reply]
Then I tried to do the same with quadrilaterals... But the problem is that angles are not enough to describe the shape of a quadrilateral, so the linear iteration of angles only tell us half of the story, and the thing is a bit more complicated. What is true about angles is that: if under your construction a quadrilateral produces a sequence of circumscribable quadrilaterals, then the corresponding sequence of angles converge to (π/4,π/4,π/4,π/4). pma (talk) 20:31, 16 June 2009 (UTC)[reply]
A quadrilateral with angles all is a rectangle, and a rectangle has an inscribed circle only if it is a square. Surely this is enough to show that the sequence of shapes, if it exists, converges to a square. -- Meni Rosenfeld (talk) 22:41, 16 June 2009 (UTC)[reply]
Exact. And whether there is such a sequence remains unclear to me too. I'll think a bit about it in spare time.--pma (talk) 10:25, 17 June 2009 (UTC)[reply]
Of course, what we both meant was ... -- Meni Rosenfeld (talk) 15:48, 18 June 2009 (UTC)[reply]
I tried computing the result for my example. I'm suffering heavily from numerical accuracy issues, but it seems like the sequence indeed exists and converges to a square. -- Meni Rosenfeld (talk) 23:35, 16 June 2009 (UTC)[reply]
Okay, I take that back. After fixing said issues, it is clear that my example only goes as far as trapezoid, kite, trapezoid. The latter does not have an inscribed circle. So it seems that the hard part is finding an infinite sequence. -- Meni Rosenfeld (talk) 00:02, 17 June 2009 (UTC)[reply]
I agree, one more step forces the trapezoid to be a square. But then I'm inclined to think that any sequence must stop in 3 or 4 steps unless it's made by squares... --pma (talk) 22:30, 17 June 2009 (UTC)[reply]
(OP) Thanks for replies. This was prompted by a newspaper puzzle, the problem being to get the (all different) angles of the starting quadrilateral so that the eleventh one would have integral-degree angles. The answer is (26,58,154,122) on the basis of the angle progression, but I couldn't find a way of drawing this so that the next one could have a circle inscribed. So it looks as if the compiler isn't as smart as he thinks he is.→86.132.235.58 (talk) 11:44, 18 June 2009 (UTC)[reply]
Indeed, with these angles, the only way to have an inscribed circle is to have sides , and for this quadrilateral the sequence doesn't continue. -- Meni Rosenfeld (talk) 15:48, 18 June 2009 (UTC)[reply]
So, looking at the complex function , it's got one simple pole in the interior of the contour, the pole is at , and we have . Applying the residue theorem, we multiply by 2πi to obtain
The next step is to break the contour into pieces that we can deal w/ separately. We take , and the other three follow in the usual (anti-clockwise) order. It's easy to show that the short vertical sides of the rectangle, and , become small as ; that part is no problem. That leaves and , and we can express the latter in terms of the former.
...which is not, in general, a real number. In particular, for , we get zero in the denominator.
Can some kind and knowledgeable soul tell me what I'm doing wrong? I'm very grateful for any hints you can throw me. -GTBacchus(talk) 16:07, 16 June 2009 (UTC)[reply]
If you call your original integral Ia then the integral along γ3 is expressible in terms of I1−a, not quite what you calculated. Following that through you get a relation between Ia and I1−a. But there's also a trivial relationship between these two integrals which you can see if you replace x by −x in Ia. Putting the two relations together will give you a formula for Ia that looks like it should be a complex number, but is really real. Really. Chenxlee (talk) 18:22, 16 June 2009 (UTC)[reply]
Yeah, I got the γ3 integral in terms of 1-a at one point, but that didn't seem helpful, so I went back and did a change of variable instead, replacing x with -x. Did I make an error in the change of variable? -GTBacchus(talk) 18:57, 16 June 2009 (UTC)[reply]
It looks like when you made the substitution x → −x, you didn't change the limits of integration. On second thoughts you don't need to get the relation between Ia and I1−a, once you fix your limits of integration you'll get γ3 in terms of Ia and can finish your original method from there. Chenxlee (talk) 10:29, 17 June 2009 (UTC)[reply]
By gum, you're right. That just might do it... -GTBacchus(talk) 13:29, 17 June 2009 (UTC)[reply]
I love it when a complex integral comes together, to quote Hannibal Smith. Chenxlee (talk) 22:52, 17 June 2009 (UTC)[reply]
Indeed. The final answer, I have finally been able to express as a real number that looks like a real number: .
It only took the better part of a week to figure it out, too! Thanks very much for your help. :) -GTBacchus(talk) 04:34, 18 June 2009 (UTC)[reply]
You can simplify the result to . — EmilJ. 11:43, 18 June 2009 (UTC)[reply]
Ah, so you can. That's interesting: When I was looking at the function as a color-plot the other day, it was smelling very much like some kind of imaginary cosecant.
I'm still getting used to the idea that the exponential function is essentially another trig function, only sideways. Maybe more accurately, the trig functions are sideways exponentials. In a manner of speaking. The numbers e and π sure seem to know a lot about each other, at least. -GTBacchus(talk) 13:35, 18 June 2009 (UTC)[reply]
Yes, that's a very good example of it. Euler, as usual, said it well. (I hope I wouldn't be studying for a Ph.D. qualifying exam in Complex Variables without knowing about that formula!) -GTBacchus(talk) 17:18, 18 June 2009 (UTC)[reply]
Sorry, didn't mean to suggest you were unaware of it - I just love the equation and couldn't resist the opportunity to quote it! Dbfirs 00:31, 19 June 2009 (UTC)[reply]
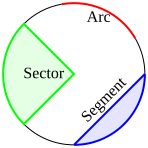
Is the area of the minor sector bounded by the equations and given by
If I'm wrong please tell me but don't tell me the answer. I have, in a sense, cheated because the two previous parts of the question asked for the area of the sectors defined by and and and and wondered if I could possibly avoid the algebraic slog that would be needed and just find a formula that works in the two special cases m=0 and b=0. —Preceding unsigned comment added by 92.4.46.28 (talk) 17:44, 16 June 2009 (UTC)[reply]
a doesn't appear anywhere in your formula, and the answer clearly does depend on a, so it can't be right. You only need to solve the problem for and , and then the general case can be reduced to it. -- Meni Rosenfeld (talk) 18:52, 16 June 2009 (UTC)[reply]
Actually you can also assume that , to which other cases are reduced by rotation. -- Meni Rosenfeld (talk) 18:59, 16 June 2009 (UTC)[reply]
I may be missing something, but those equations don't seem to span a sector. Do you mean a segment? If so, I agree that it is best to reduce the problem to a simpler one. You can very easily work out how to generalise the solution for the special case that Meni describes. --Tango (talk) 19:24, 16 June 2009 (UTC)[reply]
How can I prove that the product of two contiguous sets is always itself contiguous? I can intuitively understand it, by visualising two contiguous subsets of as contiguous horizontal and vertical lines, and their product (a subset of as a contiguous, filled rectangle. But I can't make a formal proof of it. The thing is, this used to be my homework. I couldn't do it, but then I saw someone else do it. I understood the solution fully, and then forgot it. It was an exam question less than one month later, and I couldn't remember how to do it. Can anyone at least give a hint? JIP | Talk 19:31, 16 June 2009 (UTC)[reply]
By 'continguous', do you mean connected, or perhaps path-connected? Algebraist 19:33, 16 June 2009 (UTC)[reply]
I mean connected, i.e. not able to be represented as the union of two disjoint non-empty subsets, of which either both are closed or both are open. JIP | Talk 19:41, 16 June 2009 (UTC)[reply]
Consider 'slices' of the product (i.e. sets of the form X×{y} or {x}×Y in the space X×Y). Note that if you could disconnect the product, then you could disconnect some slice, and that each slice is homeomorphic to the appropriate factor. Algebraist 19:46, 16 June 2009 (UTC)[reply]
What do you mean by "appropriate factor"? JIP | Talk 19:51, 16 June 2009 (UTC)[reply]
Sorry, I was being lazy. I mean that slices X×{y} (where y is any point in Y) are homeomorphic to X (via the obvious map), while slices {x}×Y are homeomorphic to Y. Algebraist 19:53, 16 June 2009 (UTC)[reply]
OK, now I understand the basic idea. I have to think about it some more to be able to make a formal proof. JIP | Talk 20:25, 16 June 2009 (UTC)[reply]
The following fact may be of use to you:
If U and V constitute a separation of a topological space, X, and if C is a connected non-empty subset of X, C must lie in either U or V (but not both).
Now note that each slice is connected and use the above fact.
After you have proved that, it may be an interesting exercise to show that the arbitrary product of connected sets is connected in the product topology (if you are familiar with it). If you need a hint, let us know. --PST 00:50, 17 June 2009 (UTC)[reply]







![{\displaystyle \gamma =\partial ([-R,R]\times [0,2\pi ])}](https://wikimedia.org/api/rest_v1/media/math/render/svg/06667e1620f324d8982791d360af3a79e3021727)




![{\displaystyle \gamma _{1}=[-R,R]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/390ca2a4ae7d7bf9de622b115877fe410a9bbb61)






![{\displaystyle x\in [-R,R]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f7924a22f7dac6a41fa756a385a15c07f7e34295)























![{\displaystyle \sum _{k=1}^{2n}(-1)^{[{\frac {k}{n}}]}2^{-k},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c200b2867939b3312e0df4f7c34a9cf0ae891716)
![{\displaystyle {[{\frac {k}{N}}]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/59c8b4b07e8e9b8885cafc94741b6362b0242032)
