Wikipedia:Reference desk/Archives/Computing/2008 June 24
| Computing desk | ||
|---|---|---|
| < June 23 | << May | June | Jul >> | June 25 > |
| Welcome to the Wikipedia Computing Reference Desk Archives |
|---|
| The page you are currently viewing is an archive page. While you can leave answers for any questions shown below, please ask new questions on one of the current reference desk pages. |
June 24
editDVD authoring
editCould you name me a free software for MS Windows or Mac OS X that will burn a DVD video (or create an ISO for the above). Well, I guess, beggars cannot be choosers so freeware would be fine as well. The only condition is that the app should not keep crashing forever like DVD flick tends to do with my Toshiba Satellite. :( Kushal (talk) 03:00, 24 June 2008 (UTC)
- For working with isos, I see no reason to get fancy. I use cdrecord and mkisofs (both command-line utilities). I don't need pretty animations. Just type a command to make an iso or burn an iso on the command line and wait for it to get done. -- kainaw™ 03:43, 24 June 2008 (UTC)
- Can I make ISOs of DVDs that will play on most DVD players, if not all? Hmm ... let me look up mkisofs. Thanks, kainaw. any more takers? Kushal (talk) 04:08, 24 June 2008 (UTC)
- The program you use to make and burn the isos has very little to do with what DVD players will play the DVD. Of course, if you make an ISO from scratch (not from an existing DVD), you will be responsible for building the chapter and menu structure so the DVD players can properly play the DVD. This is just like making an audio CD. You can't just throw random mp3s on a disk and call it an audio CD. It must have the proper track format. -- kainaw™ 04:28, 24 June 2008 (UTC)
I am kind of looking for a software like DeVeDe for Windows or Mac OS X. I know the software that burns the iso does not matter but DeVeDe makes iso files which I can stick into the dvd burning program and DeVeDe kind of makes the dvd iso's. Kushal (talk) 10:02, 24 June 2008 (UTC)
I just stuck with trusty old Wubi to go to DeVeDe in Ubuntu 8.04. Then I let it work all night long and got an iso. I will probably go back to Ubuntu and use Brasero or something to actually burn it into a disc. I was hoping a similar approach was possible on Windows or a Mac. Please help. Kushal (talk) 18:03, 24 June 2008 (UTC)
Contactless smart cards
editAre there contactless smart cards which function identical to regular contact smart cards except for their physical interface? We are experimenting with using smart cards with Linux and looking in to contactless smart cards to store RSA private keys for login authentication, file encryption, and e-mail S/MIME signing/encryption. Is this possible to do with current contactless smart cards? Is it secure (both in transmission and having a PIN with the same protections as PINs on most contact smart cards)? What additional resources are there for investigating this? Thanks 192.156.33.34 (talk) 04:21, 24 June 2008 (UTC)
- All smartcards I've worked with do nothing more than respond with a number when a signal hits them. That number could be a public key in some sort of PGP system. But, you'll need to make your own smartcards if you want them to perform internal logic and perform a proper PGP handshake. As for having the cards store private keys - that is a bad idea. They respond to a signal that may easily be duplicated. What happens with some guy puts a laptop in his backpack and has it emitting the "give me your keys" signal to all nearby smartcards and gets in an elevator with all the executive personnel? In that case, you want smartcards with about a half-inch range. They may as well be contact smartcards. -- kainaw™ 04:32, 24 June 2008 (UTC)
- Yea, I'm looking for a contactless smart card that's identical to a regular smartcard and can do processing. For your private key statement, that's why I was wondering if the transmission is secured and has authentication with a PIN, as it would mitigate any issue with eavesdropping or brute forcing -- with regular smart cards, if an incorrect PIN has been entered too many times it locks. We can do everything we want with regular smart cards, but the feature of being able to just tap your wallet or ID badge on a sensor seems very convenient and I'm trying to research its feasibility. —Preceding unsigned comment added by 192.156.33.34 (talk) 05:34, 24 June 2008 (UTC)
- See Oyster card and contactless smartcard? -- SGBailey (talk) 09:07, 24 June 2008 (UTC)
Transferring big files between PC's
editWhat is the simplest and cheapest way to move big files (15 MB) one time between an old, bare bones PC with Windows 98 SE to a P4 running XP? Can I hook up my network card from my new machine to the old one and email the files to myself? Or will a USB drive work? Or do I have to hook up a CD or DVD burner? Bear in mind that I'm a hardware klutz. Clarityfiend (talk) 09:35, 24 June 2008 (UTC)
- Flash drives are not an ideal solution here because Windows 98 SE might require you to supply device drivers manually. Burning CDs for 18 MB files seems wasteful unless you do multisession optical disc authoring. Wiring the two computers together seems like overkill because it will not be used any often. Kushal (talk) 10:15, 24 June 2008 (UTC)
- I prefer to just remove the hard drive(s) from the old PC and hook them up to the new PC. This can either be done temporarily to transfer files, or permanently, if the new PC can accommodate both the old hard drives and the new hard drives. If it's only temporary, you can disconnect the cables for the CD and/or DVD drives and use them to attach to the old hard drives. Stores also sell a "docking station" to convert an internal hard drive to an external, USB hard drive. StuRat (talk) 10:22, 24 June 2008 (UTC)
- StuRat's solution is good and might be my preferred solution (on a PC; on a Macintosh I'd use either the built-in networking or Target Disk Mode), but for a self-described "hardware klutz", Kermit or ZMODEM might be nice, albeit old-fashioned solutions. But those are almost certain to work given the null modem connecting cable.
- I'd go with the USB flash drive. They're easy and cheap (you can get a 2GB flash drive for $20 nowadays). Yeah, you might have to look up some drivers the first time you plug it into the old one. But that's a one time thing. It's a lot easier for a novice than removing the hard drive, much less re-connecting it and getting all the jumpers right (and potentially having to fiddle with the BIOS, depending on how the system is set up).--98.217.8.46 (talk) 13:23, 24 June 2008 (UTC)
- If the old computer has an ethernet card, and had IP installed it is quite simple to connect a cross over cable, set up static IP numbers, such as 10.0.0.1 and 10.0.0.2 and share the drive from the old computer, then map the drive on the new computer and copy. It is a lot easier and faster than connecting the serial ports and trying Zmodem. Though if the old computer has USB, that is what I would use myself. Graeme Bartlett (talk) 21:35, 24 June 2008 (UTC)
- Oy vey! I guess it's time to get somebody else to do it. Thanks anyway. Clarityfiend (talk) 08:20, 25 June 2008 (UTC)
Apostrophe
editWhere did this apostrophe ' come from ? Not ’ (the real apostrophe) or ′ (the prime symbol) but ' (misuse for the real apostrophe). In the article, we can read : The typewriter apostrophe ( ' ) was inherited by computer keyboards but where exactly ? Who invented this approximative symbol ? VIGNERON * discut. 09:35, 24 June 2008 (UTC)
- Our article on quotation mark glyphs has some answers. In summary:
- Vertical or "ambidextrous" double quotation marks were introduced on typewriters to reduce the number of keys on the keyboard; the single apostrophe was presumably made vertical for consistency of appearance in typed text.
- Early computer keyboards inherited the standard typewriter layout.
- Vertical quotation marks and apostrophes became enshrined in the ASCII character set as ASCII codes 34 and 39 respectively.
- Various word processing systems and programs adopted different (and often inconsistent) conventions for distinguishing, interpreting and presenting quotation marks, apostrophes, grave accents and primes.
- This confusion has been somewhat reduced by the introduction of separate Unicode codes for left/right single/double quotation marks. Gandalf61 (talk) 10:56, 24 June 2008 (UTC)
- But before computer ? (uh, maybe it’s not the right place to ask that) Is it Christopher Latham Sholes or someone before who introduce this misuse ? VIGNERON * discut. 11:05, 24 June 2008 (UTC)
- Typewriters existed long before computers; as VIGNERON said, it's from there that the "tradition" comes.
- There's a lot of obviously false propaganda in these answers. ASCII doesn't have a "vertical apostrophe". ASCII is not a font. It assigns the code 00100111 to represent apostrophe. It doesn't specify the shape of the apostrophe; if yours are vertical and you don't like them that way, blame your font designer, not the character set. There aren't any vertical apostrophes in the VGA 8x16 font I'm looking at right now, and it surely predates the wide adoption of Unicode. I distinctly remember the apostrophe character in the good old 8x8 font of the Commodore 64 (not ASCII but similar), and it was sloped, not vertical. The idea that the basic apostrophe character is vertical seems to be a straw man set up by Unicode pushers; those of us who happily use smaller, more manageable character sets have never seen this mythical vertical apostrophe! It apparently only exists in the U+0027 slot of Unicode fonts, and its purpose is to rile up users so they'll switch to using the non-ASCII-compatible apostrophes. How about this: demand a good apostrophe glyph in the U+0027 slot, and then ASCII text will look fine! --tcsetattr (talk / contribs) 21:22, 24 June 2008 (UTC)
- [citation needed] ! 00100111 is maybe ' or ’ in ASCII but in Unicode 00100111 is U+0027 and clearly ' (’ is U+2019). Unicode is maybe partially responsible but on keyboards the apostrophe is vertical, and keyboards exist long before Unicode. Cdlt, VIGNERON * discut. 10:15, 25 June 2008 (UTC)
- There's a lot of obviously false propaganda in these answers. ASCII doesn't have a "vertical apostrophe". ASCII is not a font. It assigns the code 00100111 to represent apostrophe. It doesn't specify the shape of the apostrophe; if yours are vertical and you don't like them that way, blame your font designer, not the character set. There aren't any vertical apostrophes in the VGA 8x16 font I'm looking at right now, and it surely predates the wide adoption of Unicode. I distinctly remember the apostrophe character in the good old 8x8 font of the Commodore 64 (not ASCII but similar), and it was sloped, not vertical. The idea that the basic apostrophe character is vertical seems to be a straw man set up by Unicode pushers; those of us who happily use smaller, more manageable character sets have never seen this mythical vertical apostrophe! It apparently only exists in the U+0027 slot of Unicode fonts, and its purpose is to rile up users so they'll switch to using the non-ASCII-compatible apostrophes. How about this: demand a good apostrophe glyph in the U+0027 slot, and then ASCII text will look fine! --tcsetattr (talk / contribs) 21:22, 24 June 2008 (UTC)
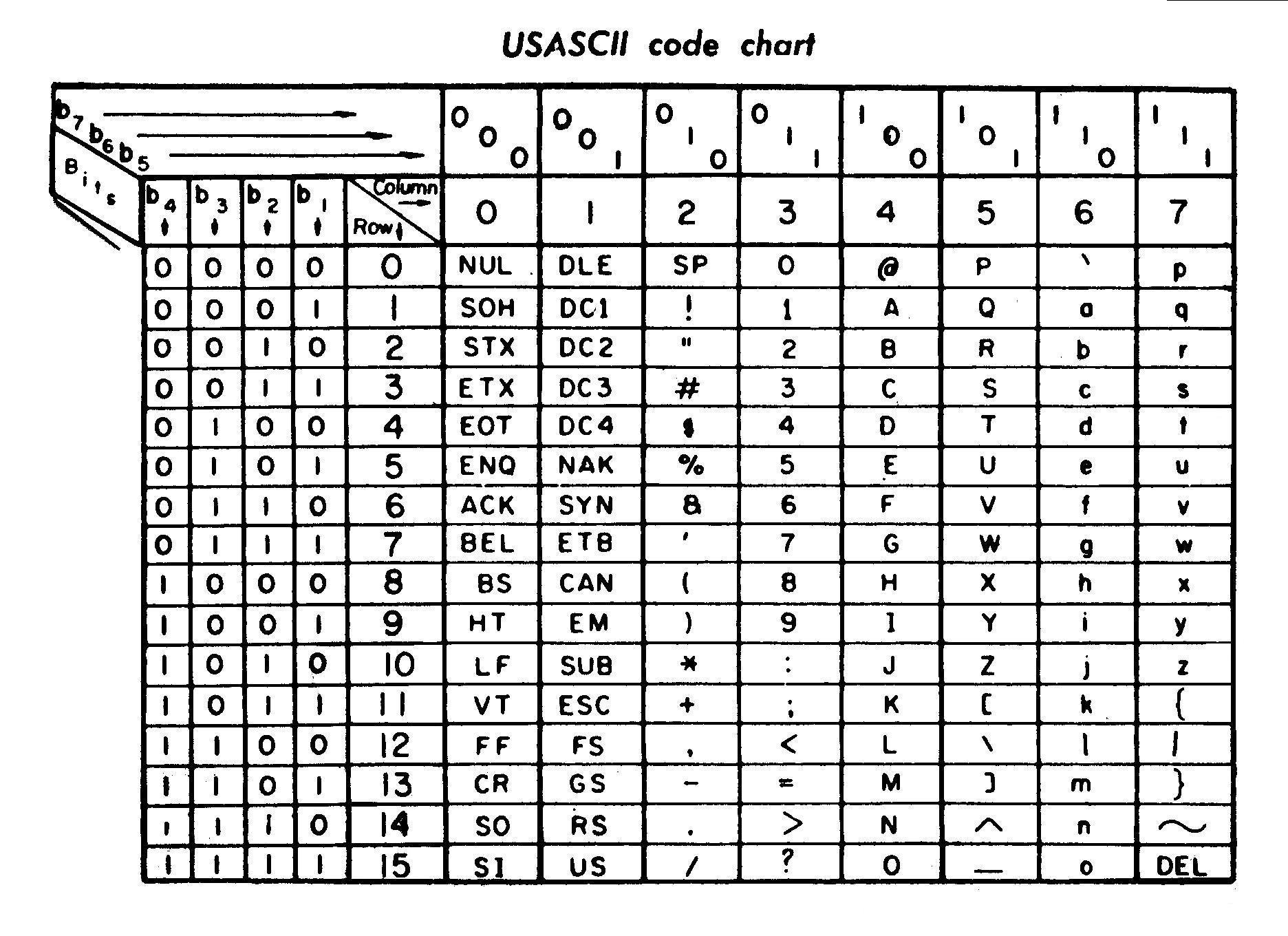
- You want a citation for what apostrophes on ASCII systems look like? What would that be, a picture of my screen? This thing here: ' is not vertical on my screen, nor on anyone else's if they use a decent font. You want a citation for the fact that ASCII doesn't mandate a vertical apostrophe? How about the chart in the history section of our ASCII article, which appears to be taken from the actual ASCII standard? Look at the apostrophe in that chart. It's not vertical! It's slanted (view the full-size image to see it clearly.) That's the definitive ASCII apostrophe. See also the first external link in that same article, which leads to more charts that also don't have vertical apostrophes. In the original 1963 version of ASCII, the apostrophe was one of those pretty curvy ones! Also you'll see that the apostrophe character in ASCII was originally intended to double as an acute accent, which would not make sense if it was expected that it even might be vertical. Unicode claims to have ASCII as a subset, but really U+0027, defined as a vertical apostrophe, is not equivalent to the corresponding code point in ASCII, which has always been defined as a "real" apostrophe. So Unicode has entirely invented the "problem" of the vertical aposotrophe, and then tried to blame it on ASCII. Now that you mention it, I do see a vertical apostrophe on my keyboard. It's been a while since I had to look at the symbols on the keyboard to know which key is which, so I didn't think of that while writing my earlier comments. Keyboards may vary. I don't have an early-ASCII-era keyboards to check, but http://images.google.com/images?q=commodore+64+keyboard shows a counterexample to the notion "nobody thought of the slanted apostrophe until the glorious Unicode revolution!" If you want to blame ASCII for causing a disaster, look at the backslash. Ugh. Let me know which facts you still have any doubt of.
- (I can't believe I wrote 00100111. I meant 0100111 of course; ASCII is 7-bit.) —Preceding unsigned comment added by Tcsetattr (talk • contribs) 11:01, 25 June 2008 (UTC)
- I just want a citation that ASCII is just encoding and don’t precise the appearance of the apostrophe (or better: precise that apostrophe is curved or slope) or the liste where ' is not vertical. In most (all?) fonts, ' is vertical (logically according to Unicode). On commodore 64 keyboard, is 7 a ’, or ´, or both ? (I didn’t know Commodore before, it’s pretty interresting). I don’t want to blame ASCII, nor Uicode. What I really want is the history of ' and ’ (with reliable facts, not just Google images, moreover we have commons:Category:Commodore 64 on Commons). The patent of QWERTY keyboard may be useful too (but I don’t know where to find it). One other point, in some informatic language (like Bash or Wikitext) the vertical apostrophe and the sloped one are needed (or have differents uses), with your font how could you distinguish them ? Cdlt, VIGNERON * discut. 12:48, 25 June 2008 (UTC)
- Let's reduce indentation here... Did you read what I just wrote? Look at the damn chart! That chart is the ASCII specification. Direct link to image locations: http://upload.wikimedia.org/wikipedia/commons/8/85/ASCII_Code_Chart-Quick_ref_card.jpg http://www.wps.com/projects/codes/X3.4-1963/page5.JPG http://www.wps.com/projects/codes/New-ASCII/page3.JPG http://www.wps.com/projects/codes/Revised-ASCII/page1.JPG - those are my citations. What's preventing you from seeing them? If you want official copies, I believe ANSI still wants you to pay for them. I don't even know where to begin getting rid of your misconception that a particular shape of apostrophe is mandated by the character set. That's just not what a character set is.
- I also don't know how to interpret your assertion that ' is vertical is "most (all?) fonts" immediately after I pointed out examples of fonts where it's not vertical; except that you're just trying the win the argument by being the last one to repeat your assertion. Fonts in which this character ' is vertical are Unicode fonts. Most pre-Unicode fonts did not have vertical apostrophe. And that is exactly what I've been saying all along: Unicode mandated a vertical apostrophe where previously they were not non-existent, but not in any way mandated, and not even the common usage. So yes I'm sure you can download a thousand unicode fonts and 999 of them will have vertical apostrophes. You'd be proving my point for me. Unicode fonts have a vertical apostrophe in position U+0027; ASCII fonts have various shapes there, some curved, some straight but slanted, some vertical; much like ASCII fonts also vary in whether there is a dot in the zero, or a slash in the zero, or neither.
- And in response to "On commodore 64 keyboard, is 7 a ’, or ´, or both" its primary usage was as an apostrophe in English text. It was the equivalent of the ASCII apostrophe. It may have been put to other uses, but probably not as an accent mark since the on-screen font had no accented characters to display. With backspace and overstrike on a printer, maybe. This was the 80's, we weren't hung up on "correct" usage of characters, we were happy just to have something that looked vaguely like the character we wanted to type.
- I'm also not sure what you mean with your bash reference. Bash is an implementation of the POSIX shell (descended from the Bourne shell) with some extensions. It is therefore a very old language, designed in the early years of ASCII, and doesn't require any characters outside the ASCII set. I'd be surprised to learn that bash actually assigns any syntactical significance to the Unicode quote/apostrophe characters, except possibly as synonyms for the ASCII ones.
- I'm also not aware of any use of the Unicode apostrophe in wiki markup, but that's a language I haven't studied much. With the basic ASCII apostrophe you can make italic and bold text; what does the other apostrophe do?
- We are missing a piece of the history, and I'm not sure where to look it up. Why did Unicode decide to declare U+0027 to be a vertical apostrophe, going against the common practice of actual ASCII implementations? Because of that decision, you think I'm typing vertical apostrophes, but I'm not. I'm typing ASCII apostrophes, and they're nice and curvy on my screen because I'm not using a Unicode font. Your font, following the Unicode mandate, is not rendering them as intended. In the other direction, you type fancy Unicode apostrophes, thinking I'll see them as the beautiful curvy kind, but actually I can't see them at all because I'm not using Unicode (I see question marks or gibberish). That all may be seen as just a sad mistake. But when we've got someone making false statements like "Vertical quotation marks and apostrophes became enshrined in the ASCII character set as ASCII codes 34 and 39 respectively" it's more than a mistake - it's a Unicode supporter blaming ASCII for an incompatibility that Unicode is actually responsible for. Slander! I won't stand for it! --tcsetattr (talk / contribs) 20:12, 25 June 2008 (UTC)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
aabout alcatel
editcan you help me on alcatel omni pcx enterprise working on IP. —Preceding unsigned comment added by Kapiltci (talk • contribs) 11:01, 24 June 2008 (UTC)
- We might be able to help, but you'll have to ask an actual question. --LarryMac | Talk 12:59, 24 June 2008 (UTC)
- Does IP mean Intellectual property? Kushal (talk) 17:57, 24 June 2008 (UTC)
- More likely it means Internet protocol, because "The Alcatel-Lucent OmniPCX Enterprise is an integrated, interactive communications solution for medium-sized businesses and large corporations." ([1]). --LarryMac | Talk 19:01, 24 June 2008 (UTC)
Hornet 3.0 for Vista
editI enjoy playing old games and one of those is Hornet 3.0 by Graphsim. I used to play it on my older Compaq laptop which ran XP and had an older processor and stuff but I recently bought a new laptop which uses Vista with newer stuff. Installing the demo as a test, the thing did not work. What should I do? --Blue387 (talk) 14:22, 24 June 2008 (UTC)
- Hmm - I assume you mean F/A-18 Hornet 3.0. According to the specs here [2] it runs under W95, W98 or WME which rules out Dosbox. I take it running in compatibility mode doesn't work? Exxolon (talk) 00:44, 25 June 2008 (UTC)
gmail e-mail notifier for multiple gmail accounts...
editI'd like to be able to be notified of new e-mails in real-time, but for multiple gmail accounts. I found one such solution "gmail notifier", but unfortunately it requires java, which I wouldn't like to have running all the time. Is there anything else like that? Thank you. —Preceding unsigned comment added by 82.120.108.31 (talk) 14:55, 24 June 2008 (UTC)
- Digsby will do this, but it might be more memory-hungry than you'd be happy with if you're only using it as an email notifier. — Matt Eason (Talk • Contribs) 16:48, 24 June 2008 (UTC)
- Webmail Notifier works on Mozilla Firefox including the latest Firefox 3 browser. Please give that a look. Kushal (talk) 17:55, 24 June 2008 (UTC)
Database of current digital cameras?
editI had a Kodak v570 which was fantastic because it had an ultra-wide angle lens (23mm equivalent on a 35mm camera). However, it seems impossible to find any modern cameras that have a wide angle anywhere close to that. Anyone know of a model like that or a website that would contain the 35mm equivalents for lenses of all currently available cameras? --70.167.58.6 (talk) 16:10, 24 June 2008 (UTC)
Is this what you are after? [3] —Preceding unsigned comment added by 86.129.227.206 (talk) 23:10, 24 June 2008 (UTC)
Linux kernel 0.01
editIve been given this link to the linux kernel 0.01: http://www.kernel.org/pub/linux/kernel/Historic/ but don't know which item on there is the kernel. Can anyone help me? --RMFan1 (talk) 17:45, 24 June 2008 (UTC)
- Both the one ending in .gz and the one ending in .bz2 contain the kernel source code. They just use different compression formats. --Sean 18:56, 24 June 2008 (UTC)
Java Help
editYes, this is homework; however, I'm fairly sure that I know what needs to be done and I just need to know a specific function to do what I want to do. While it is easy to look up a function to see what it does, unfortunately it is very difficult to find a function that does a specific thing, so I'd just like to ask for some help here. I hope this doesn't break the "homework" rule.
I'm writing a basic hangman program to introduce myself to basic string manipulation, but i'm stuck. I have an array with a dictionary of words to use (one word per element) and then a rng to grab a word from the array. I then put that word into an array, one character per element. I can use the *.length function to get the number of letters in the array. I want to then print one underscore per character that exists in the array, as is standard in hangman, but I don't know how to do that. I was thinking maybe a loop, where it prints one underscore while the number of underscores is less than the number of letters in the word, but that seems overcomplicated. Anyone? 152.23.160.76 (talk) 18:35, 24 June 2008 (UTC)
- Your approach sounds fine. Let us know if you have any trouble doing it. --Sean 19:01, 24 June 2008 (UTC)
- You might want to print an underscore and a blank space for each letter, so that the player can easily tell how many letters are in the word. --LarryMac | Talk 19:06, 24 June 2008 (UTC)
- That is specifically what "for" loops are made for. For each letter in the array, print an underscore. -- kainaw™ 19:20, 24 June 2008 (UTC)
- Or an underscore with a space next to it, as Larry suggests. Zain Ebrahim (talk) 20:33, 24 June 2008 (UTC)
- That is specifically what "for" loops are made for. For each letter in the array, print an underscore. -- kainaw™ 19:20, 24 June 2008 (UTC)
- You might also find something useful for that purpose in the utility class java.util.Arrays. Good luck! --Prestidigitator (talk) 17:27, 25 June 2008 (UTC)
what in the world is this: �?
editI found it in the word g�teaux here. Thanks. --MagneticFlux (talk) 20:11, 24 June 2008 (UTC)
- It appears to be an error in the unicode. The wrong code for that letter may have been used, as it doesn't display in serif or monospace. weburiedoursecretsinthegarden 20:21, 24 June 2008 (UTC)
- So what exactly do the symbol, the FF, and the FD mean? --MagneticFlux (talk) 20:27, 24 June 2008 (UTC)
- Per list of Unicode characters: U+FFFD � Replacement Character. --—— Gadget850 (Ed) talk - 20:39, 24 June 2008 (UTC)
- FFFD in hexadecimal is the Unicode replacement character which is your computer's way of telling you "the input was complete nonsense at this point". Being smarter than your computer, I can tell you what was supposed to be there: It should have been a "LATIN SMALL LETTER A WITH CIRCUMFLEX", as in Gâteaux differential. The text is encoded in the Latin-1 character set, but the web server is incorrectly labeling it as UTF-8. In fact, that web server is really confused; it's returning 2 Content-Type headers, one right and one wrong. --tcsetattr (talk / contribs) 20:45, 24 June 2008 (UTC)
My (domain) name is Hannah Montana
editHello. Is it possible for someone to completely refuse to give up a (pretty relevant) domain name if no bad faith can be proven? For example, let's say that someone's real name was Hannah Montana, and she decided to take up the domain hannahmontana.com, simply for a blog or a quite innocent personal page. But then the Hannah Montana comes up and wants the domain for her. What if, despite any oodles of cash offered, the first Hannah didn't want to give up the domain? Could Hannah Montana the brand-- I mean the artist, somehow demand the domain for her legally? Thanks in advance, Kreachure (talk) 20:42, 24 June 2008 (UTC)
- A similar example occurred with mikerowesoft.com. Mike Rowe being his real name was not enough. Also, I seem to remember that aol.org used to be registered to someone other than America Online, and they were able to forcibly take control of it which was a big disappointment back when some of us still thought there was a meaningful distinction between ".org" and ".com"; AOL clearly not being a non-profit organization. The whole point of a hierarchy after all is that sibling nodes like COM. and ORG. can independently assign meaning to descendant names without worrying about collisions, right? OK, enough of that... the real answer: The Big Company Always Wins. --tcsetattr (talk / contribs) 21:01, 24 June 2008 (UTC)
- The big company always wins is right. The Pirate Bay at one time owned the IFPI's domain. They turned it into something like the "International Federation of Pirates and the Internet." It was taken away from them. Mac Davis (talk) 23:38, 24 June 2008 (UTC)
- I seem to remember the little guy winning once when a video game player who called himself "Sting" registered sting.com, and the easy-listening singer Sting tried to take it away from him and lost in court ... but not for long, it seems. --Sean 00:20, 25 June 2008 (UTC)
- I suppose the only answer to this question would be considered "legal advice" because it would require some analysis of the case law in the district in question. I don't think any legislation exists that supports this action specifically, so past judge decisions would be the only basis for legal argument.
- Of course, there is plenty of legislation on "copyrights" and intellectual property, so I'm sure many of the original cases would involve arguments around that. The results of those original cases would be highly influenced by the judge's decisions/interpretations and those decisions would be perfect candidates for appeal, if the loser had the money (the big companies always win...) NByz (talk) 23:05, 24 June 2008 (UTC)
- PS. the MikeRoweSoft.com case was settled out of court, so it can't be used as any sort of precedent in a future ruling. Chances are that if you're in a situation like you describe, the company will choose to just buy you out rather than spending the money to duke it out in court. I think most squatters would accept the settlement (as the potential court costs (=the maximum acceptable settlement) could be pretty high) NByz (talk) 23:10, 24 June 2008 (UTC)
- The prohibition against "legal advice" has nothing to do with analyzing case law. It does not prohibit speculative answers. It just prohibits the sorts of answers that could be construed as actually being regulated legal advice. (And names are not covered by copyright law—that's trademark law. Very different animal.) --98.217.8.46 (talk) 02:11, 25 June 2008 (UTC)
- PS. the MikeRoweSoft.com case was settled out of court, so it can't be used as any sort of precedent in a future ruling. Chances are that if you're in a situation like you describe, the company will choose to just buy you out rather than spending the money to duke it out in court. I think most squatters would accept the settlement (as the potential court costs (=the maximum acceptable settlement) could be pretty high) NByz (talk) 23:10, 24 June 2008 (UTC)
Nissan.com is currently owned by a Mr Nissan, a computer company owner. Nissan cars have been trying to bully it out of him for years. Also there's a current attack by the owners of CS Lewis (Narnia author)'s properties after someone bought narnia.mobi so their daughter could have it for an email address. Fucking corporate whores - fuck them all. Exxolon (talk) 00:40, 25 June 2008 (UTC)
The real problem here is that internet domain registration is sort of a no-man's land. Domain names have quickly become very valuable currency in a way they were probably never anticipated to become, and there is next to no real regulation of them. While it's of course very cheeky to blame the big companies here, one can understand their interest in the subject, and it's the same "freedom" that allows a few nobodies to register the same names as big companies that allows other cyber-squatters to have 90% of domain names point to just nothing, just junk. --98.217.8.46 (talk) 02:11, 25 June 2008 (UTC)
- A dramatic and famous case in the UK is the bullying of domain owners containing the word "easy" on its name by the Easyeverything company (EasyInternet and EasyJet). GoingOnTracks (talk) 12:57, 25 June 2008 (UTC)
- DNS was always meant to be a no-man's land. It establishes mnemonics for IP addresses (and, separately, IP addresses to which to send mail), and that's all. The reason that companies (in particular) want to have their trademark as a domain name (preferably with .com, .org, .biz, etc.) is twofold: the first is the unfortunate fact that many people treat the DNS as if it were a search engine, and blithely type "Nissan" (or whatever other name) into a URL field (without scheme, TLD, or path) and expect it to "work". The second is the understandable but untenable desire for their advertisements' URLs to be trivial to remember. Of course, this "working" is dependent on the clearly false notion that there is precisely one website by that "name" — that is, that the name has precisely one meaning as a Web identifier. But there are far too many collisions to ever resolve, even among Trademark Owners: is "Sonic" the restaurant or the hedgehog? Does "Apple" sell iPods or the music for them? Is "Nissan" a car manufacturer or a computer shopkeeper? It depends on whom you ask!
- The answer, of course, is to construct a tool that does more than maintain a simple mapping from names onto objects: perhaps a tool that knows many different names (or keywords) for each site, and can produce the entire list associated with any set of keywords in a fashion that allows for disambiguation and favors sites that are generally thought to be important. As it would have to consult the text of individual pages, rather than merely aggregating the entire contents of servers, it would need to somehow discover the relationships between different portions of information: conveniently a mechanism for elucidating such relationships in a standard way exists. Since it would perform a graph search on the Web, we could call it a "web search engine", and we could even use it to directly find the "most famous" entity associated with a given name. I imagine that once this "search" catches on, the bitter disputes over "scarce" domain names will pass from memory. --Tardis (talk) 15:54, 25 June 2008 (UTC)
Wow, the nissan.com case is quite interesting. The owner of the nissan.com domain (AND the nissan.net domain as well!), Uzi Nissan, has spent almost ten years duking it out in court with Nissan Motors, and he's been able to keep his domain until this day. I don't think it's been at all cheap to do so, but still. Nissan has done almost everything there is to do to get the domain for themselves, but so far they have failed. It's good to know that at least in some instances the big companies don't win. Thanks all. Kreachure (talk) 15:49, 25 June 2008 (UTC)
Using Sharepoint as an External Website
editMy office has microsoft server 2007 w/ Sharepoint 3.0. We've set up a couple of internal workspaces and sites, but are interested in using sharepoint (hosted from our server here) to act as place for other firms in our industry to collaborate and discuss things.
Can the server be set up to do this? Are there security concerns re: the integrity of the rest of our intranet?NByz (talk) 22:19, 24 June 2008 (UTC)
Dreamweaver
editWith dreamweaver installed, how can i change the files that it automatically opens so when i click on a php file it opens in wordpad rather than dreamweaver by default? —Preceding unsigned comment added by 86.129.227.206 (talk) 23:06, 24 June 2008 (UTC)
- Right click on your php file, go to Open with>Choose, choose dreamweaver, and make sure you check always use selected program to open this type of file. Mac Davis (talk) 23:35, 24 June 2008 (UTC)
- I've already tried that, but dreamweaver must overpower it. —Preceding unsigned comment added by 86.129.227.206 (talk) 00:02, 25 June 2008 (UTC)
- It can't "overpower" it. It is not a struggle. Dreamweaver is probably set up to "claim" those file extensions whenever it turns on. Look in its preferences and there might be a way to turn it off. --98.217.8.46 (talk) 02:13, 25 June 2008 (UTC)
- I've already tried that, but dreamweaver must overpower it. —Preceding unsigned comment added by 86.129.227.206 (talk) 00:02, 25 June 2008 (UTC)
- I have a Mac OS X version of CS3, this is what I do: Preferences>Filetypes/editors. Change the settings for php files there. That should stop the overpowering/auto-claiming at startup. Mac Davis (talk) 17:21, 25 June 2008 (UTC)
- Brilliant, thanks. .php files still show a dreamweaver icon, but they now open in my prefered editor. Better than nothing. —Preceding unsigned comment added by 86.157.169.147 (talk) 23:22, 25 June 2008 (UTC)
- The icon mess-up can be fixed in windows by getting TweakUI. Open it (after installing; Start -> Run; enter tweakui and click "OK") and click "repair" on the left side. Choose "rebuild icons" and click "repair now". JeremyMcCracken (talk) (contribs) 05:46, 26 June 2008 (UTC)