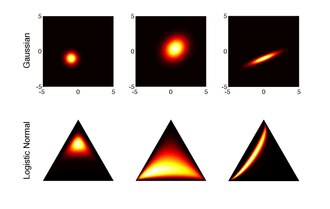
In probability theory, a logit-normal distribution is a probability distribution of a random variable whose logit has a normal distribution. If Y is a random variable with a normal distribution, and t is the standard logistic function, then X = t(Y) has a logit-normal distribution; likewise, if X is logit-normally distributed, then Y = logit(X)= log (X/(1-X)) is normally distributed. It is also known as the logistic normal distribution,[1] which often refers to a multinomial logit version (e.g.[2][3][4]).
|
Probability density function  | |||
|
Cumulative distribution function  | |||
| Notation | |||
|---|---|---|---|
| Parameters |
σ2 > 0 — squared scale (real), μ ∈ R — location | ||
| Support | x ∈ (0, 1) | ||
| CDF | |||
| Mean | no analytical solution | ||
| Median | |||
| Mode | no analytical solution | ||
| Variance | no analytical solution | ||
| MGF | no analytical solution | ||


![{\displaystyle {\frac {1}{2}}{\Big [}1+\operatorname {erf} {\Big (}{\frac {\operatorname {logit} (x)-\mu }{\sqrt {2\sigma ^{2}}}}{\Big )}{\Big ]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f866d537580a7e284ff45c5b6ba44282405d5437)

A variable might be modeled as logit-normal if it is a proportion, which is bounded by zero and one, and where values of zero and one never occur.
Characterization
editProbability density function
editThe probability density function (PDF) of a logit-normal distribution, for 0 < x < 1, is:

where μ and σ are the mean and standard deviation of the variable’s logit (by definition, the variable’s logit is normally distributed).
The density obtained by changing the sign of μ is symmetrical, in that it is equal to f(1-x;-μ,σ), shifting the mode to the other side of 0.5 (the midpoint of the (0,1) interval).

Moments
editThe moments of the logit-normal distribution have no analytic solution. The moments can be estimated by numerical integration, however numerical integration can be prohibitive when the values of are such that the density function diverges to infinity at the end points zero and one. An alternative is to use the observation that the logit-normal is a transformation of a normal random variable. This allows us to approximate the -th moment via the following quasi Monte Carlo estimate


![{\displaystyle E[X^{n}]\approx {\frac {1}{K-1}}\sum _{i=1}^{K-1}\left(P\left(\Phi _{\mu ,\sigma ^{2}}^{-1}(i/K)\right)\right)^{n},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/72f6194558f091fda796896edd4b1cb390fbf201)
where is the standard logistic function, and is the inverse cumulative distribution function of a normal distribution with mean and variance .[clarification needed]


Mode or modes
editWhen the derivative of the density equals 0 then the location of the mode x satisfies the following equation:

For some values of the parameters there are two solutions, i.e. the distribution is bimodal.
Multivariate generalization
editThe logistic normal distribution is a generalization of the logit–normal distribution to D-dimensional probability vectors by taking a logistic transformation of a multivariate normal distribution.[1][5][6]
Probability density function
editThe probability density function is:

where denotes a vector of the first (D-1) components of and denotes the simplex of D-dimensional probability vectors. This follows from applying the additive logistic transformation to map a multivariate normal random variable to the simplex:




![{\displaystyle \mathbf {x} =\left[{\frac {e^{y_{1}}}{1+\sum _{i=1}^{D-1}e^{y_{i}}}},\dots ,{\frac {e^{y_{D-1}}}{1+\sum _{i=1}^{D-1}e^{y_{i}}}},{\frac {1}{1+\sum _{i=1}^{D-1}e^{y_{i}}}}\right]^{\top }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8d9c97b2fcf6aa03dd19a3bd83b6ff96f2deb7f7)
The unique inverse mapping is given by:
- .
![{\displaystyle \mathbf {y} =\left[\log \left({\frac {x_{1}}{x_{D}}}\right),\dots ,\log \left({\frac {x_{D-1}}{x_{D}}}\right)\right]^{\top }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dd6953a8dc1335421fa50d4956fe959f724590a5)
This is the case of a vector x which components sum up to one. In the case of x with sigmoidal elements, that is, when
![{\displaystyle \mathbf {y} =\left[\log \left({\frac {x_{1}}{1-x_{1}}}\right),\dots ,\log \left({\frac {x_{D}}{1-x_{D}}}\right)\right]^{\top }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/41624f2bfd185e5111e9d4ec2339495bf420d3ff)
we have

where the log and the division in the argument are taken element-wise. This is because the Jacobian matrix of the transformation is diagonal with elements .

Use in statistical analysis
editThe logistic normal distribution is a more flexible alternative to the Dirichlet distribution in that it can capture correlations between components of probability vectors. It also has the potential to simplify statistical analyses of compositional data by allowing one to answer questions about log-ratios of the components of the data vectors. One is often interested in ratios rather than absolute component values.
The probability simplex is a bounded space, making standard techniques that are typically applied to vectors in less meaningful. Aitchison described the problem of spurious negative correlations when applying such methods directly to simplicial vectors.[5] However, mapping compositional data in through the inverse of the additive logistic transformation yields real-valued data in . Standard techniques can be applied to this representation of the data. This approach justifies use of the logistic normal distribution, which can thus be regarded as the "Gaussian of the simplex".


Relationship with the Dirichlet distribution
edit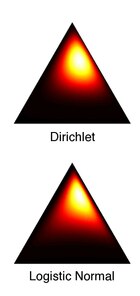
The Dirichlet and logistic normal distributions are never exactly equal for any choice of parameters. However, Aitchison described a method for approximating a Dirichlet with a logistic normal such that their Kullback–Leibler divergence (KL) is minimized:

This is minimized by:
![{\displaystyle {\boldsymbol {\mu }}^{*}=\mathbf {E} _{p}\left[\log \left({\frac {\mathbf {x} _{-D}}{x_{D}}}\right)\right]\quad ,\quad {\boldsymbol {\Sigma }}^{*}={\textbf {Var}}_{p}\left[\log \left({\frac {\mathbf {x} _{-D}}{x_{D}}}\right)\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b35a2ca21cc73c82be7e6e40e22cc8e3e297d36e)
Using moment properties of the Dirichlet distribution, the solution can be written in terms of the digamma and trigamma functions:





This approximation is particularly accurate for large . In fact, one can show that for , we have that .



See also
edit- Beta distribution and Kumaraswamy distribution, other two-parameter distributions on a bounded interval with similar shapes
References
edit- ^ a b Aitchison, J.; Shen, S. M. (1980). "Logistic-normal distributions: Some properties and uses". Biometrika. 67 (2): 261. doi:10.2307/2335470. ISSN 0006-3444. JSTOR 2335470.
- ^ http://people.csail.mit.edu/tomasz/papers/huang_hln_tech_report_2006.pdf [bare URL PDF]
- ^ Peter Hoff, 2003. Link
- ^ "Log-normal and logistic-normal terminology - AI and Social Science – Brendan O'Connor". brenocon.com. Retrieved 18 April 2018.
- ^ a b J. Atchison. "The Statistical Analysis of Compositional Data." Monographs on Statistics and Applied Probability, Chapman and Hall, 1986. Book
- ^ Hinde, John (2011). "Logistic Normal Distribution". In Lovric, Miodrag (ed.). International Encyclopedia of Statistical Sciences. Springer. pp. 754–755. doi:10.1007/978-3-642-04898-2_342. ISBN 978-3-642-04897-5.
Further reading
edit- Frederic, P. & Lad, F. (2008) Two Moments of the Logitnormal Distribution. Communications in Statistics-Simulation and Computation. 37: 1263-1269
- Mead, R. (1965). "A Generalised Logit-Normal Distribution". Biometrics. 21 (3): 721–732. doi:10.2307/2528553. JSTOR 2528553. PMID 5858101.
External links
edit- logitnorm package for R