Wikipedia:Reference desk/Archives/Computing/2013 July 10
| Computing desk | ||
|---|---|---|
| < July 9 | << Jun | July | Aug >> | July 11 > |
| Welcome to the Wikipedia Computing Reference Desk Archives |
|---|
| The page you are currently viewing is an archive page. While you can leave answers for any questions shown below, please ask new questions on one of the current reference desk pages. |
July 10 edit
Using SSL with a Server without a DNS Domain Name edit
Is there a standard way of using SSL with a server on a private network that has no real DNS domain name? The clients in this case are software systems that know the server by a private IP address. I can think of some ways to make SSL work but I wonder what the standard practice is, or if there is one. 173.49.12.2 (talk) 04:25, 10 July 2013 (UTC)
- You can use self signed certificate, or run your won certificate authority and sign your own certificates. Import your authority certificate into your web browsers. Graeme Bartlett (talk) 10:04, 10 July 2013 (UTC)
- But what do you use as the subject (the CN in particular) in the cert for the server? The name should be one by which the clients know the server. I guess you can use the server's (private) IP address, but it feels "wrong" and it's not clear whether the (non-browser) clients will support it. Another possibility is to give the server some private domain name (perhaps a .local one) and make the clients use that instead of an IP address. The name can be resolved using a local DNS service or hosts files. What is the standard practice, if there's one? --173.49.12.2 (talk) 12:33, 10 July 2013 (UTC)
- I don't know about "standard" but many larger companies use a local DNS (or sometimes WINS) for secure sites within their organisations. They often don't use self-signed certificates directly, but a self-signed signing certificate. That way the one certificate can be added to the organisation's browsers and it can then verify multiple internal sites. In effect it is a local Certificate Authority. -- Q Chris (talk) 07:53, 11 July 2013 (UTC)
- But what do you use as the subject (the CN in particular) in the cert for the server? The name should be one by which the clients know the server. I guess you can use the server's (private) IP address, but it feels "wrong" and it's not clear whether the (non-browser) clients will support it. Another possibility is to give the server some private domain name (perhaps a .local one) and make the clients use that instead of an IP address. The name can be resolved using a local DNS service or hosts files. What is the standard practice, if there's one? --173.49.12.2 (talk) 12:33, 10 July 2013 (UTC)
Coding and Minecraft edit
I have tried to view webpages and watch videos about learning to use Java, but it appears to be too difficult to remember and use. How can I learn Java online without forgetting or finding it too difficult?
Also, how do create new mobs and blocks for Minecraft, again the stuff I looked at appears to be too difficult for me?
Please assist. 92.0.111.155 (talk) 05:13, 10 July 2013 (UTC)
- Don't expect to learn programming by reading and viewing only. You need to actually do it. I would suggest to start with a friendlier language than Java - check out Python and in particular, try to work your way through the Python tutorial. Once you got the knack of programming in general, moving to another language in the same paradigm is fairly easy. Learning a new paradigm is not, but is very satisfying ;-). Good luck! --Stephan Schulz (talk) 14:16, 10 July 2013 (UTC)
- For your Minecraft question here's a tutorial which claims to be easy for beginners - I can't verify though because I don't play Minecraft... --Yellow1996 (talk) 16:04, 10 July 2013 (UTC)
- I cannot get that to download 92.0.111.155 (talk) 21:47, 10 July 2013 (UTC)
- Oh - sorry about that, the page must be old because one of the links is to Megaupload, a service which ceased to exist over a year and a half ago. This is the Minecraft wiki's page for mod creating, though it says it requires some knowledge of Java. I guess you'll need to learn the basics of that language before you do any modding. Good luck! --Yellow1996 (talk) 00:53, 11 July 2013 (UTC)
- I don't have anything Minecraft specific (never played it), but I do a lot of modding and amateur game development. Reading about the theory of programming and what's actually going on (and the right way to do it) is useful; but what really helped solidify concepts for me was taking existing programs/mods, reading through them, then coming up with small changes, trying them, and seeing if they conformed to what I thought. Sometimes doing things this way can help you with difficult ideas since if you aren't advanced enough yourself to implement them, you can't play with them; whereas modding someoneelse's implementation can give you immediate and visible feedback on what the components do.Phoenixia1177 (talk) 07:41, 13 July 2013 (UTC)
Why do computers have such a hard time when it comes down to simple tasks? edit
Why exactly can computers make beds? Or change diapers and such? The less intelligent humans that I know can do it without any mental effort. If we let the computer extra time, like some hours, would it manage to make a bed? OsmanRF34 (talk) 16:30, 10 July 2013 (UTC)
- Why do we continue to let Osman ask questions like this? Shadowjams (talk) 06:56, 11 July 2013 (UTC)
- Why not? If no one wanted to answer it, they wouldn't. It may be bordering the "we do not answer predictions" clause in the posting guidelines, but I largely interpret that to mean "go away trolls". This seems a legitimate question based on trying to understand the operation of a very complex, modern technology. -Amordea (talk) 17:03, 11 July 2013 (UTC)
- Why do we continue to let Osman ask questions like this? Shadowjams (talk) 06:56, 11 July 2013 (UTC)
- It's not the computers' fault, it's the people's :) A less intelligent human may indeed make beds easily, but it takes lots and lots of intelligence to be able to write a set of instructions on how exactly to do it (step by step, outlining every step in meticulous detail). And don't forget the instructions on how to deal with various situations that may arise in the process. Try creating a list of all the things that can go wrong when you are making the bed and you'll appreciate the enormity of the task! All computers do is follow the instructions, and if the instructions are lousy, so is the outcome.—Ëzhiki (Igels Hérissonovich Ïzhakoff-Amursky) • (yo?); July 10, 2013; 16:39 (UTC)
- Well, do computers need to know exactly? Machine learning and such can deal with many not well-defined cases, and the bed is a 'closed' system (in the sense that you know how many sheet are there, it's not like driving, when lots of things can happen). Add to it that you could put RFID tags to help the computer know where the sheets are. OsmanRF34 (talk) 16:44, 10 July 2013 (UTC)
- But they do need to know exactly; that's the nature of computers. Everything they do boils down to zeroes and ones, choices between on and off. Any operation a computer/robot perform is the result of following a set of instructions in an applicable situation. If the situation is not ideal (say, a pillow fell on the floor, and the robot can't see it), then the fall-back instructions are followed to rectify it, but, of course, someone needs to anticipate this kind of problem and to write a set of instructions to deal with it. Machine learning can deal with many ill-defined cases, but once again, someone needs to tell the machine how to deal with them (and to anticipate the problems in the first place).—Ëzhiki (Igels Hérissonovich Ïzhakoff-Amursky) • (yo?); July 10, 2013; 16:51 (UTC)
- Well, do computers need to know exactly? Machine learning and such can deal with many not well-defined cases, and the bed is a 'closed' system (in the sense that you know how many sheet are there, it's not like driving, when lots of things can happen). Add to it that you could put RFID tags to help the computer know where the sheets are. OsmanRF34 (talk) 16:44, 10 July 2013 (UTC)
- (edit conflict) It's because the computers have no understanding of the real world - save that which we tell them. You couldn't just throw a computer into a situation and expect it to figure it out without some prior information. The closest to real learning is machine learning but that still takes human intervention. We could program a computer to operate a robot which could make a bed; but as for a computer which learns the method of how to make one itself from nowhere, I don't think that's possible (yet...) Also, something I found when I searched "computer that makes your bed" on Google: [1] --Yellow1996 (talk) 16:42, 10 July 2013 (UTC)
- Well as long as you tell it what to do with the sheet, it shouldn't be a problem. However, as Ëzhiki points out above, you need to account for many variables so that the computer knows what to do when there's a problem. I assume that nobody has really taken the time to do this (besides a few models of beds which can make themselves - but that's a little different) because making the bed is not a very complicated and time consuming task. --Yellow1996 (talk) 17:02, 10 July 2013 (UTC)
- While there are many tasks that are genuinely hard for a computer, making a bed should not be among them. The reason they cannot do it is that there is no demand for it. And there is no demand because even in highly developed countries it is cheaper to do it yourself or hire human help than to have a complex robot specialized for just one or a few tasks. The major problem with making a bed is not the algorithmic part - take 10 grad students, give them enough gear, food, caffeine, 1 year of time and a price of a million dollars per person if they figure it out, and they will figure it out. The hard part is to provide the mechanical parts within a reasonable budget (and "the mechanical parts" would probably include making the room larger so that the robot can vanish into a discrete locker when not in use).--Stephan Schulz (talk) 17:21, 10 July 2013 (UTC)
- Computers can't make beds or change diapers because they don't have arms and hands -- or eyes, for that matter. Looie496 (talk) 03:10, 11 July 2013 (UTC)
- You could design a computer that makes a bed or change a diaper. I'm sure we will someday. It's just too expensive to design and build one at the moment and the price of obtaining one would outweigh the cost of hiring someone to do it. Electronic parts are getting cheaper and more powerful all the time, though. Also, as mentioned, computers are actually quite stupid. Our programming languages are very inadequate for anything other than telling them to do low-level functions like addition and data transfer. So, the language we use to interact with computers needs to evolve, as well. We need to abstract more functions away from the programmer with more libraries that do the dirty work in the background. So, the workers you mention that make beds for a living are actually much more intelligent than any computer. They can program themselves, regulate their heartbeat and breathing without effort, process super high-definition 74-megapixel video at 12 FPS with their eyes, and process touch and very high-definition audio simultaneously. They can make the bed without any effort after training and simultaneously daydream about other things while doing so. They store 2.5 petabytes of information in their brains and that far exceeds most computers made today. Computers are slowly getting smarter. It will happen, eventually.—Best Dog Ever (talk) 04:34, 11 July 2013 (UTC)
- It's very likely the fact that computers don't have world knowledge, even the lowest intelligence people have spent their entire life accumulating experience in the real world with brains, and sensory systems, tailor suited to that task by evolution. You may be interested in the following articles: Cyc, Knowledge base, Artificial intelligence, SHRDLU, Expert system, Open Mind Common Sense, and Mindpixel.Phoenixia1177 (talk) 07:48, 13 July 2013 (UTC)
Problems with FireFox on Linux edit
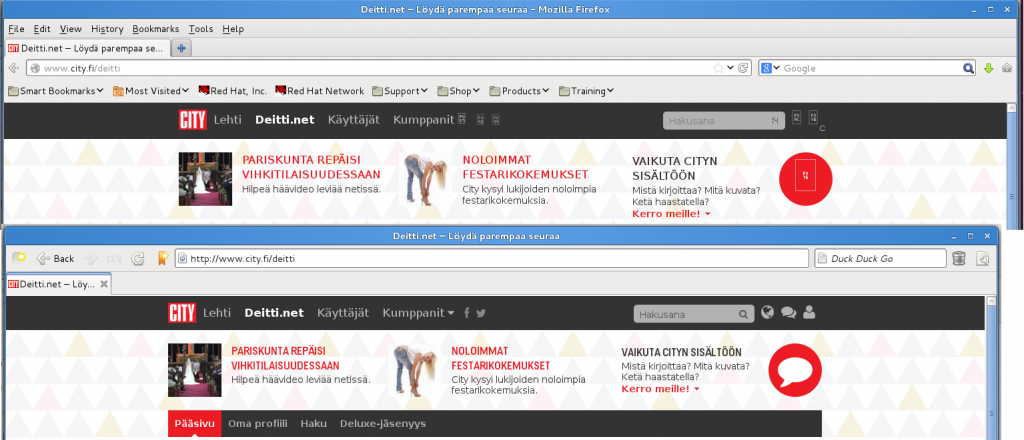
Have a look at this picture I took of an on-line dating site: http://i1291.photobucket.com/albums/b552/foobar16/Deitti_zpsbd7b73f6.png
{kind=link}
Both screenshots are from the same computer, running Fedora 17 Linux. The screenshot above is from FireFox 22.0, the screenshot below is from Midori 0.4.6.
Notice the problem? FireFox displays weird characters in the place of universally recognisable symbols, whereas Midori displays them all OK. Even better than that! At work, where I am forced to use Windows 7, FireFox has no problem displaying the symbols all correctly.
Actually, even getting to upload the picture was a hassle. FireFox wouldn't let me go past entering my sign-up information. With Midori, signing up was a doddle. Does all this mean FireFox 22.0 is hopelessly broken on Linux and I should switch to Midori instead? JIP | Talk 18:21, 10 July 2013 (UTC)
- The top one appears to be displaying unknown unicode characters, the bottom one is displaying an image. Is the top one a 2x2 grid of the numbers 0-9 and A-F? I suspect that, instead of using an actual image, the website is using a custom font with the images in it. Midori is respecting this, but Firefox isn't. As how to fix it, I don't know… CS Miller (talk) 18:43, 10 July 2013 (UTC)
- The Facebook and Twitter icons are characters in the unicode private use area (U+f098 and U+f099), rendered in the good version with the Font-Awesome icon font. In the bad case, for whatever reason, the browser has failed to load FontAwesome and is defaulting to its default sans font, which doesn't have glyphs for those codepoints (hence the hex-box fallback glyphs). I don't know why your Firefox 22 does that; on my Ubuntu box, Firefox 22 loads and renders the font icons fine. As with all problems Firefox, run in safe mode to see if one of your extensions is breaking it. -- Finlay McWalterჷTalk 18:55, 10 July 2013 (UTC)
Filling the inside of a polygon defined by vertex coordinates in Java. edit
I am looking at a problem i have in Java. There is a command i believe, whereby one can fill the area of any polygon with some color on an image buffer. The shape is defined by an array of coordinate pairs defining the vertexes of the shape. This is one of the fairly common graphics commands, i think its something like fillPoly.
My problem is thus:
I wish to make an algorithm so that two different polygons are filled with yellow. If any pixel is part of both polygons, that pixel will be orange instead of yellow when the second polygon is filled in. Furthermore, drawing a third polygon, if a pixel inside the area of this third polygon was yellow prior, it would be orange. If it was orange prior, it will now be red. The idea is to lay down consecutive polygons, with an algorithm in mind for however many shapes overlapping a pixel determining that pixel's color.
I do have a general idea for this, as i have done something similar. I can keep track of every pixel of the X*Y image buffer, with an X*Y two-dimensional array. The value of the location in the array shows how many polygons overlap there, and consequently tells what color the pixel should be when drawing a new polygon. The PROBLEM with this approach is, i would have to know given the definition of the shape as a vertex list, whether every pixel in the image is inside or outside the shape. If it is inside the shape, read that pixels current value in the array and modify the color and array as appropriate.
However, i have NO IDEA how to tell if a pixel is in a shape or not! I also fear that there may be a more elegant solution than what i am thinking of.... i was taught in programming classes to look for those elegant solutions.
Does anyone know the solution to this issue? PLEASE let me know if there is a more simple way to think of this as well, as id rather not bang my head against the wall if a better answer could stare me in the face. :)
Thank you very much in advance! 216.173.145.47 (talk) 21:20, 10 July 2013 (UTC)
- The general article about determining whether a point is in a polygon is point in polygon. You might find it easier to transform the way you store polygons to a list of triangles (see polygon triangulation) as the test for "is this point in this triangle" is straightforward. To avoid keeping a track per-pixel, you may find algorithms like the Weiler–Atherton clipping algorithm useful, where you can track the results of polygon intersections mathematically rather than brute-forcing per-pixel. As you're using Java, you can try JTS Topology Suite (but I'd encourage you to give doing it yourself a go first). Most generally, this falls within the ambit of the general topic of computational geometry. -- Finlay McWalterჷTalk 21:37, 10 July 2013 (UTC)
- It wouldn't be efficient or elegant, but if you want a simple to implement (and understand) solution, you could use the built in fillpoly method you mentioned. If it supports transparency, then you can just layer all the polygons with transparency. Anywhere that overlaps will have a different intensity than where they don't overlap. Then you can go through the pixels and remap the colors to match what you want. A geometric solution would certainly be faster and more elegant, and implemented well it would just as easy to read and understand (keeping the math abstracted away). 209.131.76.183 (talk) 14:13, 11 July 2013 (UTC)
I confess i do much like this more simple way of soing it. However, one thing i dont like about it is i think every shape needs to be laid down before the coloring scheme can be applied. I would prefer a method that will work for laying down the shapes one by one. Perhaps i can lay down a gray color for each shape and have an array of colors that are the combo of the gray shape with the underlaying other shapes, and that could be detected and fiddled with. 216.173.145.47 (talk) 16:05, 12 July 2013 (UTC)
Mail on Darwin Unix edit
I am a Unix novice (trying valiantly to learn on Mac OS X though) and one thing I would like is the ability to use the mail command in the shell. I can't readily find any information about setting it properly on the web though (or, at least, not any that is readily recognisable or intelligible to me), so I wondered if anyone here might know where I could find a suitable set of instructions, or, if it's not too demanding, even walk me through it? Thanks. meromorphic [talk to me] 22:59, 10 July 2013 (UTC)
- Does this thread help? If not, one of our Unix masters will probably be able to assist you better! --Yellow1996 (talk) 01:00, 11 July 2013 (UTC)
- You probably want a full-blown mail client - like Alpine. Alpine is free software but it's not easy to set up if you're a total novice. Instructions are available for Building and Installation.
- If you really are on a Mac, you can also use mail - the mail utility: x-man-page://mail (You can copy that URL to your browser!) It's the official man page that's built in to your system, documenting the command-line mail command. Nimur (talk) 02:29, 11 July 2013 (UTC)